TDM 40200: Project 6 — 2023
Motivation: Dashboards are everywhere — many of our corporate partners' projects are to build dashboards (or dashboard variants)! Dashboards are used to interactively visualize some set of data. Dashboards can be used to display, add, remove, filter, or complete some customized operation to data. Ultimately, a dashboard is really a website focused on displaying data. Dashboards are so popular, there are entire frameworks designed around making them with less effort, faster. Two of the more popular examples of such frameworks are shiny (in R) and dash (in Python). While these tools are incredibly useful, it can be very beneficial to take a step back and build a dashboard (or website) from scratch (we are going to utilize many powerfuly packages and tools that make this far from "scratch", but it will still be more from scratch than those dashboard frameworks).
Context: This is the fifth in a series of projects focused around slowly building a dashboard. Students will have the opportunity to: create a backend (API) using fastapi, connect the backend to a database using aiosql, use the jinja2 templating engine to create a frontend, use htmx to add "reactivity" to the frontend, create and use forms to insert data into the database, containerize the application so it can be deployed anywhere, and deploy the application to a cloud provider. Each week the project will build on the previous week, however, each week will be self-contained. This means that you can complete the project in any order, and if you miss a week, you can still complete the following project using the provided starting point.
Scope: Python, dashboards
Dataset(s)
The following questions will use the following dataset(s):
-
/anvil/projects/tdm/data/movies_and_tv/imdb.db
Questions
|
Interested in being a TA? Please apply: purdue.ca1.qualtrics.com/jfe/form/SV_08IIpwh19umLvbE |
Question 1
Create a directory in your $SCRATCH directory called imdb. This will be the "monorepo" that holds your source code for your dashboard — the frontend, the backend, and any other assets we may end up with. Create all the empty files and folders so your directory structure looks like the following.
imdb ├── backend │ ├── api │ │ ├── api.py │ │ ├── database.py │ │ ├── imdb.db │ │ ├── pydantic_models.py │ │ └── queries.sql │ ├── pyproject.toml │ ├── README.md │ └── templates ├── frontend └── README.md 4 directories, 8 files
Once complete, demonstrate you’ve created everything properly by running the following in Jupyter Notebook cell.
%%bash
tree $SCRATCH/imdb-
Code used to solve this problem.
-
Output from running the code.
Question 2
Okay! You are all set now. You have a sane project structure, and you (hopefully) learned all you needed to perform this next task.
First, we will go ahead and give you the contents of database.py.
import os
import aiosql
import sqlite3
from dotenv import load_dotenv
from pathlib import Path
load_dotenv()
database_path = Path(__file__).parents[0] / "imdb.db"
queries = aiosql.from_path(Path(__file__).parents[0] / "queries.sql", "sqlite3")That way, from another Python module, you can import and use database_path and queries to interact with the database.
from .database import database_path, queriesImplement you backend and create the following endpoints in your api.py file:
-
GET /titles/{title_id}— returns the title information as aTitleobject for theTitlewith the giventitle_id. -
GET /cast/{title_id}— returns the cast information as aCastobject for theTitlewith the giventitle_id. -
GET /people/{person_id}— returns the person information as aPersonobject for thePersonwith the givenperson_id.
Fill in the pydantic_models.py file with the following models: Title, Cast, CastMember, Work, and Person.
Fill in queries.sql with your aiosql queries. While there are multiple ways to do this, I used the following 4 queries: get_title, get_cast, get_person, and get_work. The former 2 accept a title_id as a parameter, and the latter 2 accept a person_id as a parameter.
The following are screenshots from calling the following endpoints.
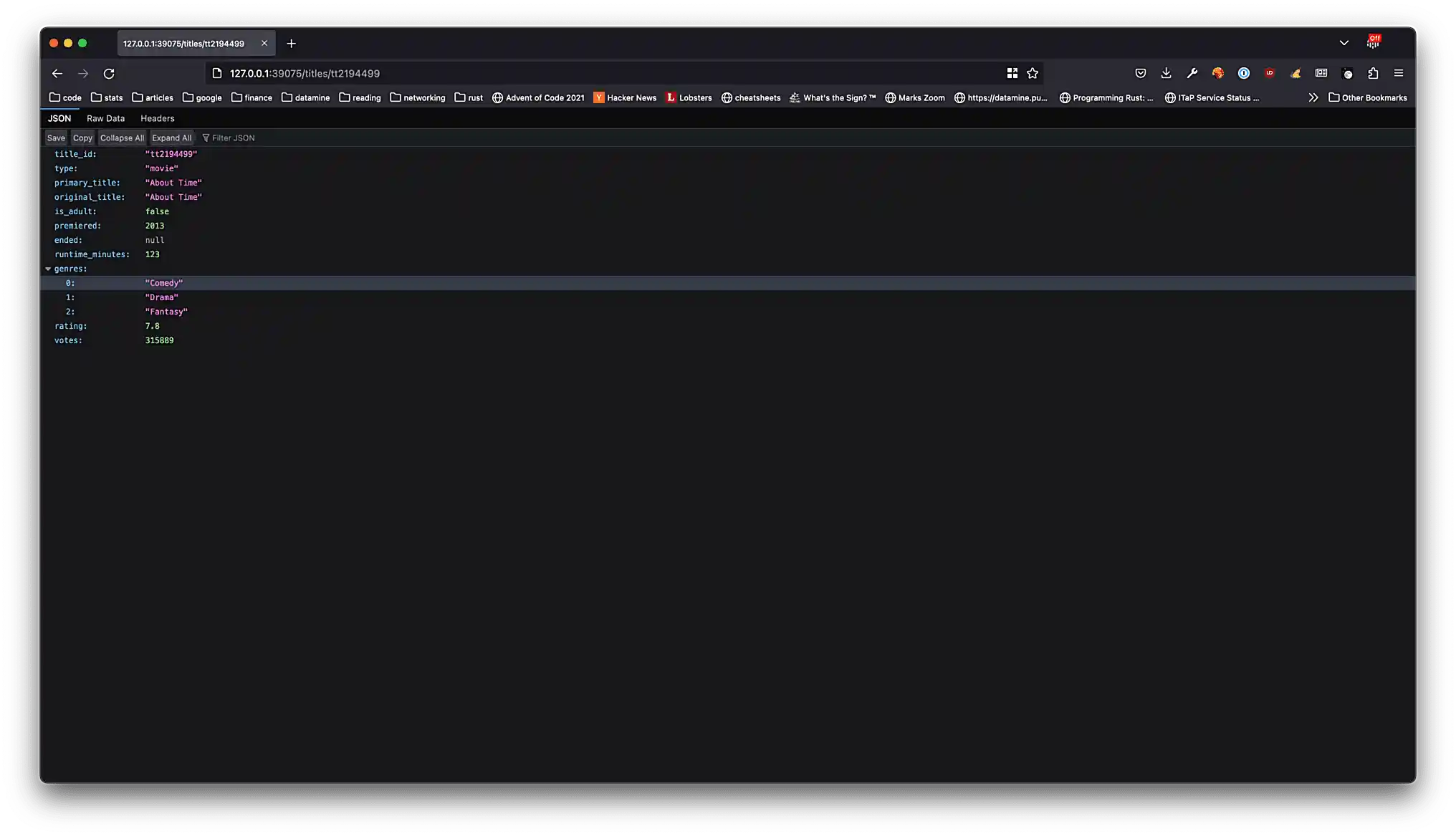
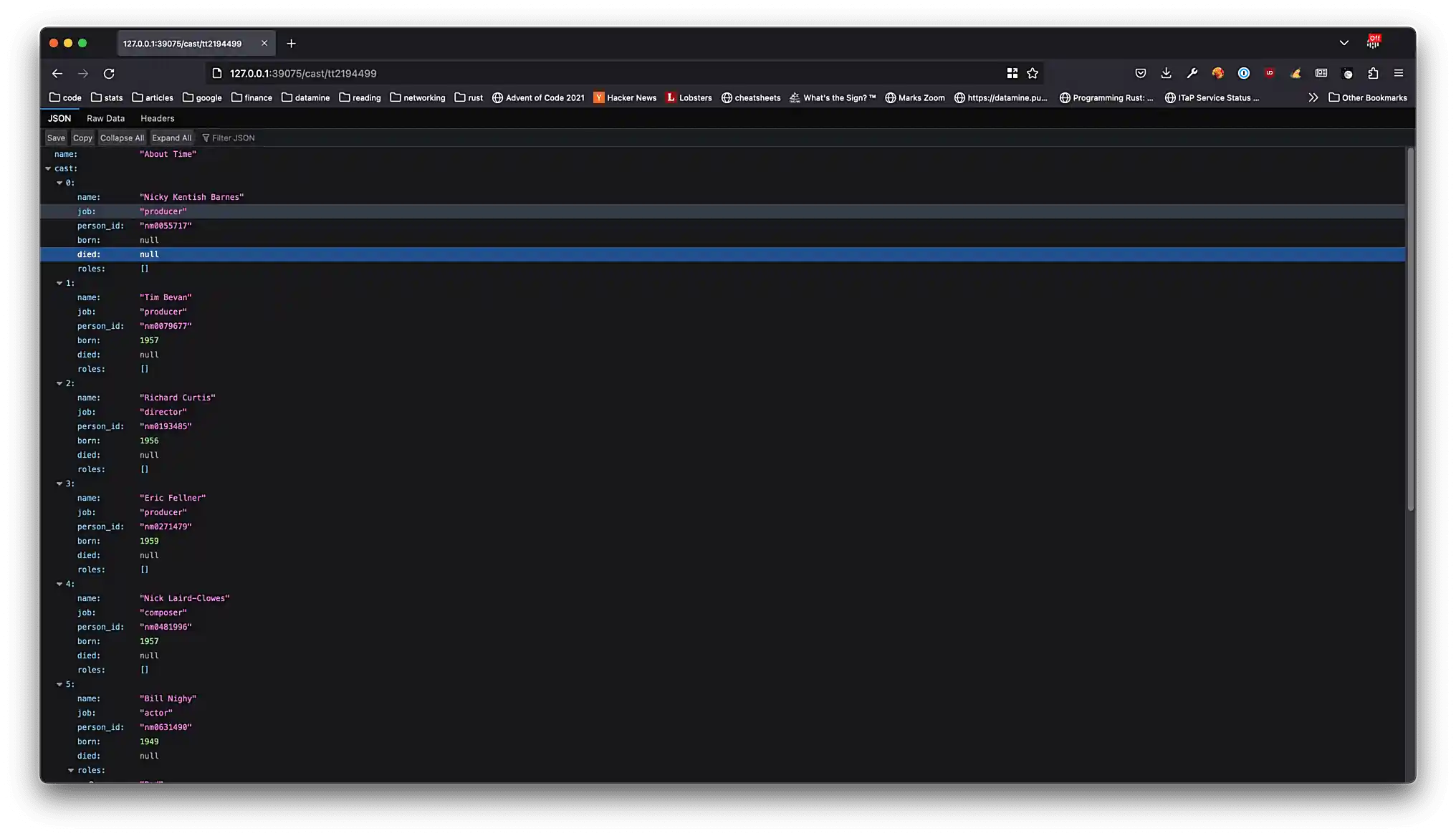
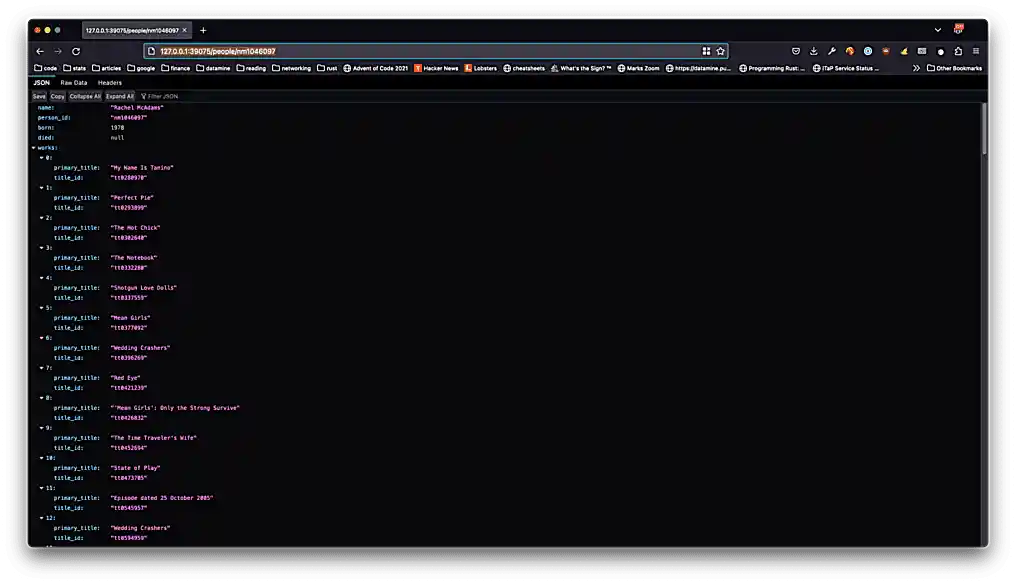
Please replicate each of these screenshots with your own screenshot for the following different endpoints.
-
GET /titles/tt1754656 -
GET /cast/tt1754656 -
GET /people/nm0748620
|
Don’t forget you can run the following to load up our environment. In addition, you can run the following to find an unused port. Then, to run your backend from your |
|
You can nest |
-
The entire directory, with all files and folders in the
imdbdirectory. -
A jupyter notebook containing the screenshots demonstrating the working endpoints.
|
Please make sure to double check that your submission is complete, and contains all of your code and output before submitting. If you are on a spotty internet connection, it is recommended to download your submission after submitting it to make sure what you think you submitted, was what you actually submitted. In addition, please review our submission guidelines before submitting your project. |