TDM 20200: Project 6 - Introduction to Polars
Project Objectives
This project aims to introduce the basics of Polars which is a modern alternative to Pandas. It is written in Rust and has a lot of features that make it faster and more efficient than Pandas especially for large datasets where Pandas may struggle. Some of the key features are lazy evaluation, data streaming, and the Arrow Columnar Format which all help make it faster than Pandas in most cases. We will be using the NYC Yellow Taxi Trip Data from September 2025 to explore these features.
Make sure to read about, and use the template found on the template page, and the important information about project submissions on the submission page.
Dataset
-
/anvil/projects/tdm/data/taxi/yellow_2025/yellow_tripdata_2025-09.parquet
The dataset for this project is the NYC Yellow Taxi trip data from September 2025. The dataset we are looking at contains taxi trip information including pickup/dropoff times, locations, distances, fares, tips, and other trip details.
The dataset contains approximately 4.2 million rows and 20 columns described in the NYC Yellow Taxi Trip Data section.
|
If AI is used in any cases, such as for debugging, research, etc., we now require that you submit a link to the entire chat history. For example, if you used ChatGPT, there is an “Share” option in the conversation sidebar. Click on “Create Link” and please add the shareable link as a part of your citation. The project template in the Examples Book now has a “Link to AI Chat History” section; please have this included in all your projects. If you did not use any AI tools, you may write “None”. We allow using AI for learning purposes; however, all submitted materials (code, comments, and explanations) must all be your own work and in your own words. No content or ideas should be directly applied or copy pasted to your projects. Please refer to GenAI page in the example book. Failing to follow these guidelines is considered as academic dishonesty. |
Questions
Question 1 (2 Points)
Getting Started with Polars
Before we hop into explaining the major differences between Polars and Pandas, lets start with some basic operations that we are already familiar with in Pandas. They are a little different syntax wise, but overall still fairly intuitive.
The dataset we are using is the NYC Yellow Cab Trip dataset and it is stored as a Parquet file, so just as we would in Pandas, we can import Polars and load in the dataset like so:
import polars as pl
df = pl.read_parquet('/anvil/projects/tdm/data/taxi/yellow_2025/yellow_tripdata_2025-09.parquet')
df.head()|
Pandas does not come with the ability to read in parquet files natively - you typically need to install |
So far this is pretty much the exact same as Pandas but we will start seeing some differences once we want to start playing with the data.
Since we are working with a time, location, and money based dataset, lets take a look at some basic statistics of how much each ride costs.
In Pandas, we would do something like this:
pandas_df['total_amount'].mean()
pandas_df['total_amount'].std()
...
# or
pandas_df['total_amount'].describe()In Polars the syntax looks more like this:
df.select(
mean=pl.col('total_amount').mean(),
std=pl.col('total_amount').std()
)
...
# or
df.select(
pl.col('total_amount')
).describe()The first main difference we notice is that we are not directly indexing onto the dataframe like we do in Pandas, instead we tell Polars what columns we want to use and what operations we want to apply to them. Then we actually apply these operations to the dataset using the .select() method.
These specified operations are called expressions which we will talk more about in a bit. At first, it might seem pointless but this opens the door to a whole new host of optimizations and ways to manipulate your data which is why Polars is so nice!
Here is the link to the documentation which goes over a lot of the functions in Polars.
We already looked at the mean and std of the total_amount column, but lets look at the median and min/max, as well. Check the documentation/look online for the syntax for the specific functions. You can also compare the output of this with the .describe() method in Polars.
Now lets create a new column called trip_duration that calculates the trip duration in minutes (difference between tpep_dropoff_datetime and tpep_pickup_datetime). In Polars, you can subtract datetime columns directly to get a Duration type, then convert it to minutes using .dt.total_minutes().
df.select(
trip_duration=(pl.col('tpep_dropoff_datetime') - pl.col('tpep_pickup_datetime')).dt.total_minutes()
)But we notice that using .select() does not actually change the dataframe, it just returns the resulting column(s) based on your specified expression. To actually see the rest of the dataframe with our new column we should use the .with_columns() method.
df.with_columns(
trip_duration=(pl.col('tpep_dropoff_datetime') - pl.col('tpep_pickup_datetime')).dt.total_minutes()
)If you want to save it to the dataframe you can just reassign it using df = df.with_columns(trip_duration=…). Now, lets move on to the filter method in Polars. Lets try to filter the dataframe to show only trips where the trip_distance is greater than 5 miles and the passenger_count is greater than 1. We can use the & operator to combine multiple conditions:
df.filter(
(pl.col('trip_distance') > 5) & (pl.col('passenger_count') > 1)
)Now lets display the shape of the filtered dataframe. The .shape attribute returns a tuple (number_of_rows, number_of_columns):
df.filter(
(pl.col('trip_distance') > 5) & (pl.col('passenger_count') > 1)
).shape1a. Code that loads the parquet file and displays first 5 rows with shape.
1b. Code calculating statistics for total_amount column (mean, median, std, min, max & describe).
1c. Code creating trip_duration column (difference between tpep_dropoff_datetime and tpep_pickup_datetime) and using with_columns() to add it to the dataframe.
1d. Code filtering trips with distance > 5 and passengers > 1, with resulting shape.
1e. (1-2 sentences) Brief comment on Polars vs Pandas syntax difference.
Question 2 (2 Points)
Understanding Expressions
In Question 1, we briefly mentioned that the operations we specify (like pl.col('total_amount').mean()) are called expressions. Expressions are one of Polars' most powerful and unique features and understanding how they work is crucial to using Polars to its full potential.
So what exactly is an expression? An expression in Polars is a description of a computation - it doesn’t actually execute until you tell it to. Its analogous to a recipe - you are describing what you want to cook and all the ingredients you need, but nothing actually happens until you decide to actually start cooking.
In Pandas, when you write something like df['tip_amount'] / df['total_amount'], it immediately calculates the result. In Polars, when you write pl.col('tip_amount') / pl.col('total_amount'), you are just creating an expression object that describes the computation. Nothing happens until you use it with a method like select(), with_columns(), filter(), or group_by().agg().
|
By describing the computation instead of instantly performing it allows Polars to perform some behind the scenes optimizations to your query before executing it. |
Let’s create our first expression. We want to calculate the tip percentage: (tip_amount / total_amount) * 100. We can do this by using the pl.col() function to reference a column named tip_amount and a column named total_amount, then divide tip_amount by total_amount and multiply by 100. Note that pl.col('tip_amount') does not know what the data is nor it is making a reference to our dataset yet. We are simply telling Polars that "there will be a column called tip_amount and a column called total_amount and we want to perform this operation on them".
tip_percent_expr = (pl.col('tip_amount') / pl.col('total_amount')) * 100
tip_percent_exprNotice that this does not return any data - it just creates an expression object.
|
Before we continue, note that the expression above could have division by zero issues if |
Now, we can actually apply it to our dataframe using the select() method to compute the result:
df.select(
pl.col('total_amount'),
tip_percent=tip_percent_expr
)If you wanted, you can also create the expression inline:
df.select(
pl.col('total_amount'),
tip_percent=(pl.when(pl.col('total_amount') > 0.0)
.then((pl.col('tip_amount') / pl.col('total_amount')) * 100)
.otherwise(0))
)This will select the column total_amount and then create a new column called tip_percent that is the result of the expression we defined.
Now let’s use with_columns() to add multiple new columns to our original dataframe. We will create:
-
fare_percent: percentage of total that is fare_amount, -
tip_percent: percentage of total that is tip_amount (using our expression from above), -
is_high_tip: a Boolean column that isTruewhen tip_percent > 20%.
df.with_columns(
fare_percent=(pl.col('fare_amount') / pl.col('total_amount')) * 100,
tip_percent=tip_percent_expr,
is_high_tip=tip_percent_expr > 20
)|
Notice how we can chain expressions together! The |
Now let’s create a more complex expression using conditional logic. Polars has a pl.when().then().otherwise() syntax (which we just saw with the more robust tip calculation) that is similar to "switch" or "case" statements in some languages. We want to categorize trips:
-
"short" if trip_distance < 2,
-
"medium" if trip_distance >= 2 and < 5,
-
"long" if trip_distance >= 5.
Based on this logic, how we wrote is_high_tip, and what you see in the tip_percent_expr expression, please create trip_category_expr to handle this separation.
|
When you want to create literal values (strings, numbers, etc.), we can use |
trip_category_expr = (...)
df.with_columns(
trip_category=trip_category_expr
)Expressions also work with filter(). Here is an example where we can filter based on the number of riders and the overall cost of the trip:
df.filter(
(pl.col('passenger_count') > 3) &
(pl.col('total_amount') > 30)
).shapeOn your own, please find all trips where the tip percentage is greater than 15% AND the total amount is greater than $30. You will need to use the tip_percent_expr expression we created earlier - you can either add it as a column first using with_columns(), or use it directly in the filter expression.
|
When combining multiple conditions in Polars, you MUST use |
2a. Code creating a tip_percent expression and using it with select() to show total_amount and tip_percent.
2b. Code using with_columns() to add fare_percent, tip_percent, and is_high_tip columns to the dataframe.
2c. Code creating a trip_category expression using pl.when().then().otherwise() logic and applying it with with_columns().
2d. Code filtering trips where tip_percent > 15% AND total_amount > $30, displaying the count/shape.
2e. Markdown explanation (2-3 sentences each) answering: What is an expression? Why don’t they execute immediately? What methods cause execution?
Question 3 (2 Points)
Lazy Evaluation
So far, we have been working with Polars in "eager" mode which is when operations execute immediately - similar to how Pandas works. But Polars has another mode called "lazy" mode which is one of its most powerful features. In lazy mode, Polars does not execute operations immediately, rather it builds up a query plan and optimizes it before executing it.
In eager mode, you tell the computer to do things sequentially and immediately, "do this now, now do that, now do this other thing". In lazy mode, you tell Polars "I want to do this, also that, and this other thing" and Polars says "okay, let me think about the best way to do all of that" and then builds up a query plan and optimizes it before executing it.
|
This is similar to how SQL databases work - you write a query, the database optimizes it, and then executes it. One of Polars big drawing points is that it brings this same blazing fast optimization to dataframes in Python. |
Since we already have our dataframe loaded in, let’s convert our dataframe to a LazyFrame. We can do this by calling .lazy() on our dataframe:
lazy_df = df.lazy()
lazy_dfNotice that when you display a LazyFrame, it does not show the data - it shows the query plan. For a newly created LazyFrame (before any operations), the plan simply shows the table source. This is because nothing has been executed yet.
Now let’s build a lazy query. We want to:
-
Filter trips where
total_amount > 50, -
Select only
trip_distance,total_amount,tip_amount, andpassenger_count, -
Group by
passenger_count, -
Calculate the mean
total_amountand meantip_amountfor each passenger count.
The group_by() method groups rows that have the same value in the specified column(s). Then agg() (short for "aggregate") applies functions like mean(), sum(), count(), etc. to each group. Think of it like SQL’s GROUP BY clause - it creates groups and then computes summary statistics for each group.
lazy_query = (lazy_df
.filter(pl.col('total_amount') > 50)
.select(['trip_distance', 'total_amount', 'tip_amount', 'passenger_count'])
.group_by('passenger_count')
.agg([
pl.col('total_amount').mean().alias('mean_total'),
pl.col('tip_amount').mean().alias('mean_tip')
])
)
lazy_queryNotice how the syntax for this is very similar to eager mode syntax (you can use the same methods like filter(), select(), group_by(), and agg()), except that even if we use lazy_df.filter().select().group_by().agg(), it still does not execute until we explicitly tell it to which we will do momentarily.
Before we do that lets take a look at the graph of the query plan - we see the query plan and the query graph with the operations we specified going from the table, to the filter, to the select, to the group_by, to the agg. But this is the "naive plan" which means that it has not been optimized yet. We can view the optimized plan by calling the show_graph() method which will show the optimized plan:
lazy_query.show_graph()|
Running |
Now we see the optimized query plan which rearranges some of the operations to be more efficient. Notice that we have 4 columns in the .select() statement and, in the unoptimized plan, we select those 4 columns after the filter. However, Polars looks at the operations and realizes we can select the columns first which will reduce the amount of information we need to filter from so it moves that up first. Also note that the optimized plan only selects 3 columns, not 4.
This is because trip_distance is selected but never used in the aggregation, so Polars eliminates it to reduce memory usage - this is called "projection pushdown" which we will learn more about in Question 5.
|
This is a simple example of query optimization - Polars rearranges operations to be more efficient. In Question 5, we will dive deeper into the specific types of optimizations Polars performs (like predicate pushdown and projection pushdown). |
Now, to actually execute the query and get results, we need to call .collect():
results = lazy_query.collect()
resultsNow let’s create a more complex lazy query. We want to:
-
Filter trips where
trip_distance > 10, -
Create a new column
tip_percentusing an expression, -
Group by whether the trip is on a weekday (use
tpep_pickup_datetime.dt.weekday()), -
Calculate the average tip percentage for weekdays vs weekends.
Use the previous example as a guide to create this more complex query. Remember we created a tip_percent_expr expression in the previous question so we can use that here too.
complex_lazy_query = (lazy_df
.filter(pl.col('trip_distance') > 10)
.with_columns(
tip_percent=tip_percent_expr
)
.with_columns(
is_weekday=pl.col('tpep_pickup_datetime').dt.weekday() < 6
)
.group_by('is_weekday')
.agg([
pl.col('tip_percent').mean().alias('avg_tip_percent')
])
)
# Show the query plan
complex_lazy_query.show_graph()
# Execute and show results
results = complex_lazy_query.collect()
results|
Notice the redundant back to back |
Now let’s compare the performance of eager vs lazy mode. We will do the same operations in both modes and time them:
import time
# Eager mode
start = time.time()
eager_result = (df
.filter(pl.col('total_amount') > 50)
.select(['trip_distance', 'total_amount', 'tip_amount', 'passenger_count'])
.group_by('passenger_count')
.agg([
pl.col('total_amount').mean().alias('mean_total'),
pl.col('tip_amount').mean().alias('mean_tip')
])
)
eager_time = time.time() - start
print(f"Eager mode: {eager_time:.4f} seconds")
# Lazy mode
start = time.time()
lazy_result = (lazy_df
.filter(pl.col('total_amount') > 50)
.select(['trip_distance', 'total_amount', 'tip_amount', 'passenger_count'])
.group_by('passenger_count')
.agg([
pl.col('total_amount').mean().alias('mean_total'),
pl.col('tip_amount').mean().alias('mean_tip')
])
.collect()
)
lazy_time = time.time() - start
print(f"Lazy mode: {lazy_time:.4f} seconds")
print(f"Lazy mode is {eager_time / lazy_time} times faster than eager mode")|
For this dataset, you might not see a huge difference in performance. But for larger datasets or more complex queries, lazy evaluation can be significantly faster because Polars can optimize the entire query (e.g., pushing filters down, eliminating unnecessary columns early, etc.). |
3a. Code converting dataframe to LazyFrame using .lazy() and displaying it.
3b. Code building a lazy query with filter/select/group_by/agg operations, showing the query plan with .show_graph().
3c. Code executing the lazy query with .collect() and displaying the results.
3d. Code creating a complex lazy query with weekday grouping (using dt.weekday()), showing both the query plan and final results.
3e. Code timing eager vs lazy execution of the same operations, with a brief comment (2-3 sentences) explaining why lazy evaluation might be faster.
Question 4 (2 Points)
Data Streaming
So far, we have been working with datasets that fit in memory with no issues. But, as we have encountered in previous projects a few times now, what happens when you have a dataset that is too large to fit in memory? This is where Polars' streaming API comes in handy.
Streaming allows Polars to process data in chunks rather than loading everything into memory at once, similar to how you can specify chunksize in Pandas when reading in a dataset.
|
Streaming is especially useful when your dataset is larger than your available RAM or you want to reduce memory usage even if the data could fit in memory. |
To use streaming, we first need to create a LazyFrame from the file. Instead of reading the entire dataset into memory first and then converting it to a LazyFrame (i.e. read_parquet().lazy()), we can use scan_parquet() which creates a LazyFrame directly from the file without loading the data into memory:
lazy_df = pl.scan_parquet('/anvil/projects/tdm/data/taxi/yellow_2025/yellow_tripdata_2025-09.parquet')
lazy_dfNotice that printing out the lazy_df shows us the query plan just like it did in Question 3 when we converted our eager DataFrame to a LazyFrame. The key difference is that scan_parquet() never loads the data into memory - it only reads from disk when you call .collect().
Now let’s create a streaming query (same general syntax as the one we worked in Question 3). We want to:
-
Filter trips where
total_amount > 100, -
Select
trip_distance,total_amount,tip_amount, andpassenger_count, -
Group by
passenger_count, -
Calculate the count of trips and mean
total_amountfor each passenger count.
Once you have written the query, to execute it with streaming, we use .collect(engine='streaming'). Without the engine='streaming' parameter, Polars would try to load all the data into memory first (if using read_parquet().lazy()) or process the dataset all at once, which could fail for very large datasets:
results = streaming_query.collect(engine='streaming')
results|
The key difference between regular lazy evaluation and streaming is that streaming processes data in chunks. Regular lazy evaluation still loads all the data into memory (or tries to), while streaming processes it piece by piece. This is why streaming is essential for datasets larger than available RAM. |
Let’s compare streaming vs non-streaming performance. We will execute the same query both ways and time them:
import time
# Non-streaming (regular lazy evaluation)
start = time.time()
non_streaming_result = streaming_query.collect()
non_streaming_time = time.time() - start
print(f"Non-streaming: {non_streaming_time:.4f} seconds")
# Streaming
start = time.time()
streaming_result = streaming_query.collect(engine='streaming')
streaming_time = time.time() - start
print(f"Streaming: {streaming_time:.4f} seconds")
print(f"Streaming mode is {non_streaming_time / streaming_time} times faster than non-streaming mode")|
For this dataset (which fits in memory), you might not see a huge difference in performance. In fact, streaming might even be slightly slower because of the overhead of processing in chunks. |
Now let’s create a more complex streaming query. We want to find the average tip percentage by hour of day:
-
Only include trips where
tip_amount > 0, -
Extract the hour from
tpep_pickup_datetime, -
Group by hour,
-
Calculate the average tip percent,
-
Sort the results by hour.
|
Notice that we can still use all the same operations (filter, with_columns, group_by, etc.) with streaming. The only difference is that we call |
4a. Code using scan_parquet() to create a LazyFrame and displaying it.
4b. Code creating a streaming query with filter/select/group_by/agg operations, executing it with .collect(engine='streaming') and displaying results.
4c. Code comparing streaming vs non-streaming execution times for the same query.
4d. Code creating a streaming query analyzing tip percentage by hour (using dt.hour()), with results sorted by hour.
4e. Markdown explanation (2-3 sentences each) answering: What is streaming? Benefits? Drawbacks? When to use streaming vs regular lazy evaluation?
Question 5 (2 Points)
Performance and Arrow Columnar Format
Throughout this project, we have mentioned that Polars is faster than Pandas, but we have not really explored why it is faster besides "optimization". In this final question, we will dive into the underlying technology that makes Polars so fast: Apache Arrow’s Columnar Format (ACF) and Polars' query engine.
Polars is built on Apache Arrow, which uses a columnar memory format. This is fundamentally different from how Pandas stores data. First lets take a look at a diagram of an example dataframe:
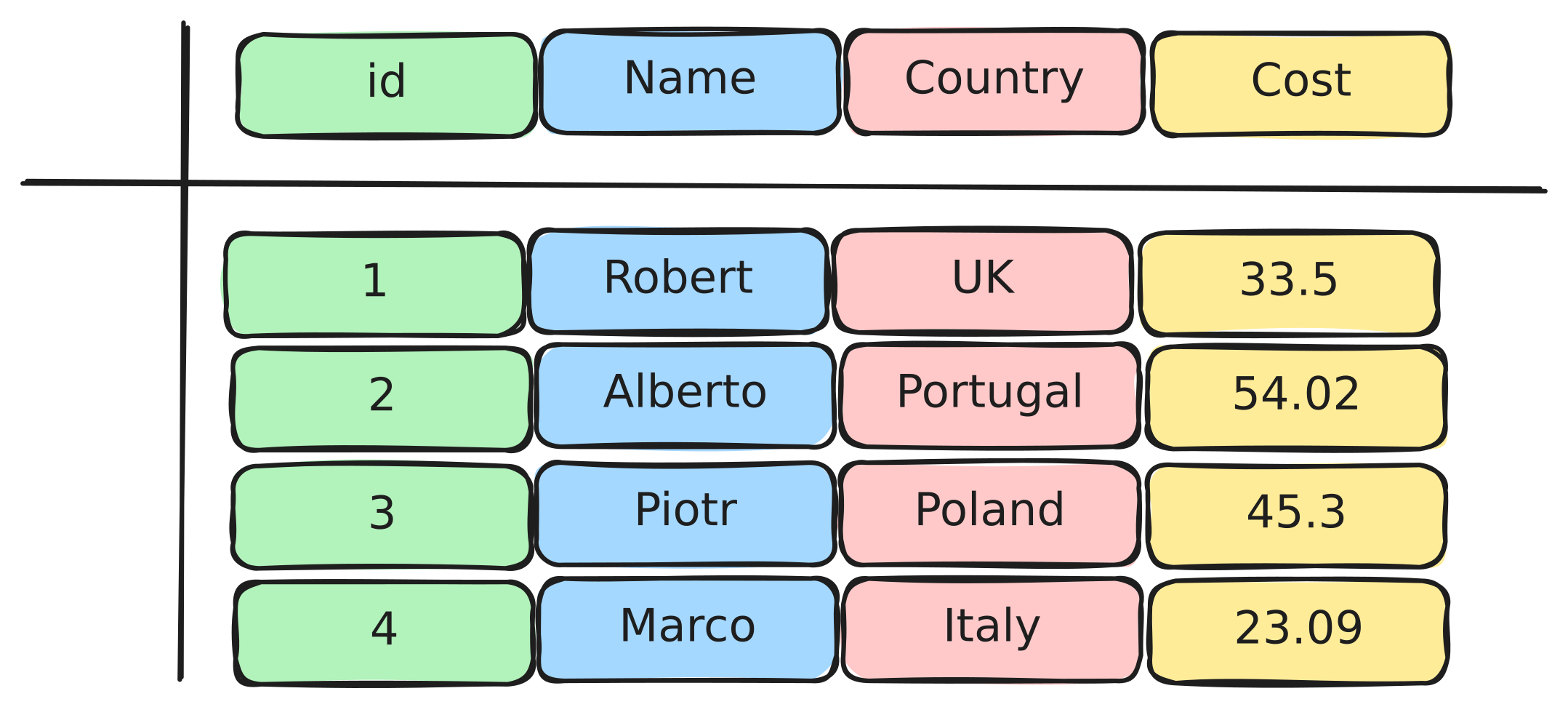
Pandas takes this dataframe and stores it row-by-row (like a spreadsheet) in memory which looks like this:

However, in Polars (using Arrow), data is stored column-by-column. This might seem like a small difference, but it has huge implications for performance.

The data for each column is stored in contiguous memory blocks which means that the data for each column is stored together in order in memory.
|
The Arrow Columnar Format (ACF) is a standardized memory format that many libraries can use. This means data can be shared between libraries (like Polars, PyArrow, DuckDB, etc.) with zero copying overhead since they all use the same memory format. |
Let’s first explore the Arrow Columnar Format. Load your dataframe and check its memory usage:
df = pl.read_parquet('yellow_tripdata_2025-09.parquet')
print(f"Estimated size: {df.estimated_size() / 1024 / 1024:.2f} MB")
print("\nSchema:")
print(df.schema)|
The |
|
Recap: In row-based storage, all the data for one row is stored together. In columnar storage, all the data for one column is stored together. This makes operations on columns (like calculating the mean of a column) much faster because the data is already grouped together. |
In Question 3, we saw that lazy evaluation allows Polars to see your entire query and optimize it before executing. Now let’s explore advanced query optimization in more detail. We will create a lazy query with multiple operations and see the specific optimizations Polars applies:
lazy_df = df.lazy()
optimized_query = (lazy_df
.filter(pl.col('total_amount') > 30)
.with_columns(
tip_percent=tip_percent_expr
)
.filter(pl.col('tip_percent') > 15)
.group_by('passenger_count')
.agg([
pl.len().alias('trip_count'),
pl.col('total_amount').mean().alias('mean_total'),
pl.col('tip_percent').mean().alias('mean_tip_percent')
])
)Now let’s see the optimized query plan:
optimized_query.show_graph()Look at the optimized query plan and explain in a comment what optimizations you see. Common optimizations include:
-
Predicate pushdown: Filters are pushed down to happen earlier (before expensive operations, sometimes at initial the data read in),
-
Projection pushdown: Only necessary columns are selected (probably the more common one).
You may also notice that Polars can combine or merge multiple operations together (like combining multiple with_columns() calls into one), which is part of its general query optimization.
Now let’s create a complex transformation and compare it to how you might do it in Pandas. We want to calculate percentage breakdowns for all cost columns:
COST_COLS = [
"fare_amount",
"extra",
"tip_amount",
"improvement_surcharge",
"congestion_surcharge",
"Airport_fee",
"cbd_congestion_fee"
]
import time
# Polars Eager Version
start = time.time()
cost_breakdown = df.select(
pl.col("total_amount").alias("total"),
*[
(pl.col(c) / pl.col("total_amount") * 100).alias(f"{c}_percent")
for c in COST_COLS
]
)
eager_time = time.time() - start
print(f"Polars time (eager): {eager_time:.4f} seconds")
print(f"Shape: {cost_breakdown.shape}")
# Polars Lazy Version
start = time.time()
cost_breakdown = lazy_df.select(
pl.col("total_amount").alias("total"),
*[
(pl.col(c) / pl.col("total_amount") * 100).alias(f"{c}_percent")
for c in COST_COLS
]
)
results = cost_breakdown.collect()
lazy_time = time.time() - start
print(f"Polars time (lazy): {lazy_time:.4f} seconds")
print(f"Shape: {results.shape}")|
Notice how we can use list comprehensions with the |
Now let’s see the equivalent Pandas version:
import pandas as pd
# Read the data
# pandas_df = pd.read_parquet('/anvil/projects/tdm/data/taxi/yellow_2025/yellow_tripdata_2025-09.parquet')
start = time.time()
pandas_cost_breakdown = pd.DataFrame()
pandas_cost_breakdown['total'] = pandas_df['total_amount']
for c in COST_COLS:
pandas_cost_breakdown[f'{c}_percent'] = (pandas_df[c] / pandas_df['total_amount']) * 100
pandas_time = time.time() - start
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Shape: {pandas_cost_breakdown.shape}")|
If you have too many versions of the dataset loaded into the kernel it will crash, so you should try to only have one pandas dataframe and one polars version to avoid this issue. If you pick a higher memory instance then you may not have to worry about this issue as much. |
Also note the difference between using the eager and lazy dataframe versions (df.select() vs lazy_df.select().collect()) for this operation compared to Pandas. The lazy version will not crash the kernel as easily because it is not loading all the data into memory at once, but in some cases it may process the data as slow or slower than Pandas. The eager version however, since it can parallelize all the operations in memory, should be much faster than Pandas.
Now let’s explore parallelization a little more. The key insight is that Polars can process different columns in parallel because they are stored separately in memory.
Let’s create a query that performs multiple aggregations on different columns:
-
length of trip in bins by passenger count,
-
mean total amount,
-
mean distance,
-
total tips,
-
max fare.
parallel_query = (lazy_df
.with_columns(
distance_bin=pl.when(pl.col('trip_distance') < 2)
.then(pl.lit('short'))
.when(pl.col('trip_distance') < 5)
.then(pl.lit('medium'))
.otherwise(pl.lit('long'))
)
.group_by(['passenger_count', 'distance_bin'])
.agg([
... # your code here
])
)
parallel_query.show_graph()In this query, we are computing multiple aggregations on different columns. Because these columns are stored separately in memory (columnar format), Polars can process these aggregations simultaneously on different CPU cores. This is the parallelization.
In row-based storage (like Pandas), this is much harder because all the data for a row is stored together, making it difficult to process different columns independently and in parallel.
This is a more complex query that might crash the notebook when trying to run .collect() on it. This can happen with large datasets when Polars tries to parallelize operations so we should use .collect(engine='streaming') instead like we mentioned in the previous questions to circumvent this issue!
# This will likely crash the notebook because it is trying to parallelize too many operations at once.
# results = parallel_query.collect()
# If that crashes, use streaming instead:
results = parallel_query.collect(engine='streaming')
results5a. Code checking memory usage with .estimated_size() and displaying schema with .schema, with markdown explanation (2-3 sentences each) of: What is ACF? How does it differ from row-based storage? Why does it allow zero-copy sharing?
5b. Code creating a complex lazy query with multiple filters and aggregations, showing the optimized query plan with .show_graph() or .explain(), with a comment explaining what optimizations you see (predicate pushdown, projection pushdown, etc.).
5c. Code performing transformation for all cost columns, with timing, and a comment comparing the performance of Pandas vs Polars (eager and lazy) and why Polars might be faster.
5d. Code creating a query grouping by multiple columns (passenger_count and distance_bin), showing the query plan, with markdown explanation (2-3 sentences) of how columnar format enables parallelization.
5e. Markdown summary (2-3 sentences each) of: Key reasons Polars is faster (ACF, query optimization, parallelization, query engine) and when to choose Polars over Pandas.
Submitting your Work
Once you have completed the questions, save your Jupyter notebook. You can then download the notebook and submit it to Gradescope.
-
firstname_lastname_project6.ipynb
|
It is necessary to document your work, with comments about each solution. All of your work needs to be your own work, with citations to any source that you used. Please make sure that your work is your own work, and that any outside sources (people, internet pages, generative AI, etc.) are cited properly in the project template. You must double check your Please take the time to double check your work. See submission page for instructions on how to double check this. You will not receive full credit if your |