TDM 20200: Web Scraping Project 3 — Spring 2025
Motivation: Now that we know how to use Beautiful Soup and lxml, we will expand and apply our skills, to achieve some systematic web scraping.
Context: We will use both Beautiful Soup and lxml, and will expand our knowledge of XPath.
Scope: Web Scraping in Python
Questions
Question 1 (2 pts)
In Project 2, Question 5, we scraped the types, names, and locations of all four parks in Indiana from the National Park Service website: www.nps.gov/state/in/index.htm
BUT we did not (yet) scrape the paragraph of information about each park from this webpage.
If we right-click on such a paragraph and use the Inspect button in Firefox, we will see that such a paragraph is contained in a p tag with no attributes. This p tag follows a div tag with class attribute equal to "list_left". Unfortunately, there are several other p tags that follow that div tag, as we already saw from Project 2, Question 5, namely:
The park types have the div tag, followed by a p with class equal to "list_leftkicker". Similarly, the park locations have the div tag, followed by a p with class equal to "list_leftsubtitle". So we want to exclude both of those results.
We can do this by using:
mytree.xpath('//div[@class="list_left"]/p[not(@class="list_left__kicker") and not(@class="list_left__subtitle")]')-
Use
lxmlwith thexpathdescribed above, to extract a list with 4 elements about the four respective parks from Indiana. -
Be sure to document your work from Question 1, using some comments and insights about your work.
Question 2 (2 pts)
Starting with the data frame from Project 2, Question 5 (which has 4 rows and 3 columns), add the results from Project 3, Question 1, as a new 4th column in this data frame, so that you have a data frame of 4 rows, corresponding to the 4 parks from Indiana.
Now solve Project 2, Question 5, and Project 3, Question 1, again but this time use California instead of Indiana. You should get a data frame with 34 rows, corresponding to the 34 parks from California, and 4 columns (again, corresponding to the type, name, location, and description of each park).
Do this one more time for Texas, creating a data frame with 18 rows and 4 columns.
-
Use Python to make a Pandas data frame with 4 rows and 4 columns, namely, 1 row per park from Indiana, with the type of park in the first column, the name of the park in the second column, the location of the park in the third column, and the description of the park in the fourth column.
-
Make an analogous data frame for parks from California, with 34 rows and 4 columns.
-
Make an analogous data frame for parks from Texas, with 18 rows and 4 columns.
-
Be sure to document your work from Question 2, using some comments and insights about your work.
Question 3 (2 pts)
Now wrap your work from Question 2 into a Python function called mystateparkinformation, which takes a 2-letter string as input, and returns a data frame that corresponds to the information about the parks from that state. For instance:
mystateparkinformation('in') should return a data frame with 4 rows and 4 columns.
mystateparkinformation('ca') should return a data frame with 34 rows and 4 columns.
mystateparkinformation('tx') should return a data frame with 18 rows and 4 columns.
Test your function on each of those three states, and then test your function on two more states of your choosing.
|
Be sure to document your function using docstrings as described, for instance, here: pandas.pydata.org/docs/development/contributing_docstring.html |
-
Make a function that takes a two-letter state abbreviation as input, and returns a data frame with 4 columns and the correct number of rows, in other words, one row per park from that state.
-
Please test your function for the inputs
'in','ca','tx', and for two other states of your choosing. -
Make sure that your function uses docstring notation that describes it well.
-
Be sure to document your work from Question 3, using some comments and insights about your work.
Question 4 (2 pts)
If you run the following code on the homepage of the NPS at: www.nps.gov you will see that it produces a list of all two-digit letter codes, for the 56 states and territories from the National Park Service website. Explain (in words) what this one line of code does. (In particular, make sure that you understand and can explain how the split function in this line of code is working.)
mystatelist = [element.attrib['href'].split('/')[2] for element in mytree.xpath('//a[@class = "dropdown-item dropdown-state"]')]Now run your function from Question 3 on each of the 56 elements in the list named mystatelist. In this way, you should create a list of 56 data frames, one for each state. This approach might help:
mylistofdataframes = [mystateparkinformation(element) for element in mystatelist]-
Explain why the code to create
mystatelistworks. -
Run your function from Question 3 on each of the 56 elements of
mystatelist, to create a list of 56 data frames, one for each state. -
Be sure to document your work from Question 4, using some comments and insights about your work.
Question 5 (2 pts)
Build the 56 data frames from Question 4 into one large data frame with 645 rows (or 638 rows?) and 4 columns. Show the first five rows and the last five rows of this data frame, to convince yourself and the TAs that you did this properly.
It might help to use an approach like this:
mylistofdataframes = [mystateparkinformation(element) for element in mystatelist]
mybigDF = pd.concat(mylistofdataframes, axis=0, ignore_index=True)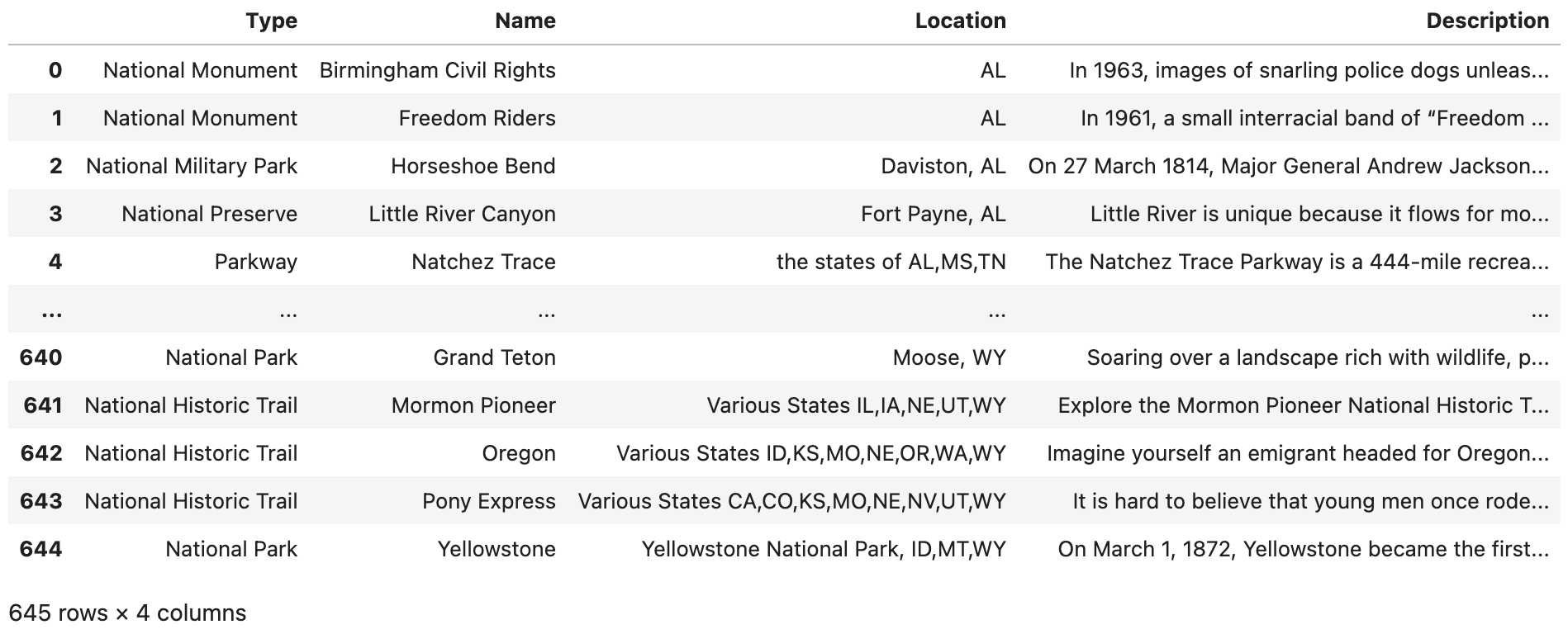
|
When Dr Ward first wrote this project, there were 645 rows altogether in the large data frame. BUT before releasing the project, there were only 638 rows. Perhaps some changes in the federal government administration led to this change? The number of rows might continue to change slightly. The graders will be flexible with you, if your work is slightly different from the work shown in the videos. |
-
Build the 56 data frames from Question 4 into one large data frame with 645 rows (or 638 rows?) and 4 columns. Show the first five rows and the last five rows of this data frame, to convince yourself and the TAs that you did this properly.
-
Be sure to document your work from Question 5, using some comments and insights about your work.
Submitting your Work
Please make sure that you added comments for each question, which explain your thinking about your method of solving each question. Please also make sure that your work is your own work, and that any outside sources (people, internet pages, generating AI, etc.) are cited properly in the project template.
Congratulations! Assuming you’ve completed all the above questions, you are learning to apply your web scraping knowledge effectively!
Prior to submitting your work, you need to put your work into the project template, and re-run all of the code in your Jupyter notebook and make sure that the results of running that code is visible in your template. Please check the detailed instructions on how to ensure that your submission is formatted correctly. To download your completed project, you can right-click on the file in the file explorer and click 'download'.
Once you upload your submission to Gradescope, make sure that everything appears as you would expect to ensure that you don’t lose any points. We hope your first project with us went well, and we look forward to continuing to learn with you on future projects!!
-
firstname_lastname_project3.ipynb
|
It is necessary to document your work, with comments about each solution. All of your work needs to be your own work, with citations to any source that you used. Please make sure that your work is your own work, and that any outside sources (people, internet pages, generating AI, etc.) are cited properly in the project template. You must double check your Please take the time to double check your work. See here for instructions on how to double check this. You will not receive full credit if your |