TDM 40100: Project 11 - Decision Tree
Project Objectives
In this project, you will explore and use decision tree modelling to analyze online customer behaviors and related revenue information contained in the dataset we will be working with. We aim to gain insight into the relationship between specific online interactions and customers' decision process, and the impact on business revenue; as well, we will understand how model performance can be evaluated and improved.
Dataset
The dataset is at /anvil/projects/tdm/data/shopper_intention/online_shoppers_intention.csv from archive.ics.uci.edu/ml/datasets/Online+Shoppers+Purchasing+Intention+Dataset.
We can also find the data at: www.kaggle.com/datasets/henrysue/online-shoppers-intention and/or github.com/gagan3012/online-shoppers-intention-/blob/master/online_shoppers_intention.csv.
|
If AI is used in any cases, such as for debugging, research, etc., we now require that you submit a link to the entire chat history. For example, if you used ChatGPT, there is an “Share” option in the conversation sidebar. Click on “Create Link” and please add the shareable link as a part of your citation. The project template in the Examples Book now has a “Link to AI Chat History” section; please have this included in all your projects. If you did not use any AI tools, you may write “None”. We allow using AI for learning purposes; however, all submitted materials (code, comments, and explanations) must all be your own work and in your own words. No content or ideas should be directly applied or copy pasted to your projects. Please refer to the-examples-book.com/projects/fall2025/syllabus#guidance-on-generative-ai. Failing to follow these guidelines is considered as academic dishonesty. |
Questions
Before getting started, we should be familiar with the concept of decision tree model. Decision Tree is one of supervised learning algorithms, used for classification or regressions. They are both fundamental tasks, but classification deals with discrete categorization of data, and regression deals with producing continuous prediction.
In the tree structure of the model, the root node represents the entire dataset and first point of decision making process. The data is split based on feature values into branches; we recursively split into smaller subsets until we can not split to make further decisions anymore. So, the internal nodes are the decision nodes where an attribute or test condition is applied, and the leaf nodes are the final decision we reach (they are also the total number of possible outcomes).
Decision tree is one of the key principles and popular because they are versatile and work on wide range of data (categorical and numerical, relationship and correlation between features), and the results are easy to interpret and visualize. To read more about the decision tree both in R and Python languages, follow the link: www.statlearning.com
Question 1 (2 points)
It is expected that the e-commerce market is to reach approximately $8 trillion by 2027, and around 20% of global retail sales are being done online. It is no doubt that online shopping and the e-commerce market continues to grow and is one of the irreplaceable methods in sales. So, it is crucial businesses understand customer behaviors when it comes to online shopping activities and their online experience. This means we need to be able to recognize patterns from the data we have, and find out what factors contribute most to customers deciding to make purchases.
The dataset we will be using contains numerous information about customers and their behaviors in online shopping. It includes features from customer types and dates to demographic and different online activities on the website. Using these data, our goal is to predict revenue and how different features are related to purchases, while understanding how the performance of our model can change and how we can get the best prediction. As mentioned earlier, we will do so by exploring decision tree modelling.
To begin, we will load and print the head of the data. As we always do, we will inspect our dataset before starting any analysis or modelling. First check the head and shape of the dataset. Then, checking for any missing or duplicate values, you should notice that below variables have missing values:
Missing Values:
Administrative 14
Administrative_Duration 14
Informational 14
Informational_Duration 14
ProductRelated 14
ProductRelated_Duration 14
BounceRates 14
ExitRates 14And below variables have duplicates
Columns with duplicates: ['Administrative', 'Administrative_Duration', 'Informational', 'Informational_Duration', 'ProductRelated', 'ProductRelated_Duration', 'BounceRates', 'ExitRates', 'PageValues', 'SpecialDay', 'Month', 'OperatingSystems', 'Browser', 'Region', 'TrafficType', 'VisitorType', 'Weekend', 'Revenue']We will remove missing values and duplicates as a part of this question. We will also convert our categorical variable into indicator variables through one hot encoding. First, check the original data types for each variable.
print("\nData Types:\n", df.dtypes)Now, we will use Pandas library’s pd.get_dummies to perform this task. By doing so, we obtain multiple new columns that take on values either 0 (not present) or 1 (present), and each column represents a unique category. Then, we can represent numerical data using binary conditions, which the tree uses as criteria for splitting.
new_df = pd.get_dummies(new_df, columns=['Month', 'VisitorType'])
print("New Data Types:\n", new_df.dtypes)-
1a. Load the csv into a pandas data frame and print the shape and head of the dataset. Write a few sentences on your observation and initial thoughts about the dataset.
-
1b. Find and show the number of missing values and duplicates, and where we have them. Also print the data types of each variable.
-
1c. Drop the missing values and remove duplicate rows. There should be zero duplicates and missing values. Show the output.
-
1d. Use
pd.get_dummiesto convert the variable type. Print the new data types.
Question 2 (2 points)
In this question, we will split the dataset into training and testing. This step is crucial for the decision tree to make good evaluations and not overfit. We can see how well model performs generally, by testing the trained part on new, unseen subset of data that was not used yet. Scikit-Learn has a model_selection module that contains various methods we can choose for evaluating models and tuning parameters. To divide the dataset, we will be using train_test_split.
from sklearn.model_selection import train_test_splitLet’s split as shown below:
X = new_df.drop('Revenue', axis=1)
y = new_df['Revenue']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=20)
y_train = y_train.to_numpy()
y_test = y_test.to_numpy()You can think of X_test as the input and y_test as the output. Revenue is what we want to predict, so it is not included in the input features. The test_size is set to 0.2, meaning we are using 80% for training and 20% for testing. random_state controls the seed for random generator. Setting this number also makes sure that the split is reproducible means the same portion of the dataset will be included every time.
decision_tree = DecisionTreeClassifier(random_state=20)
decision_tree.fit(X_train, y_train)Above will train the created decision tree using the previous training data.
-
2a. Scale the dataset and split into training and testing sets.
-
2b. Create the Decision Tree using
DecisionTreeClassifier()
Question 3 (2 points)
Let’s see the predicted outcome for our X_test feature.
y_pred = decision_tree.predict(X_test)Now, as we do with other models, we will explore some methods we can use to determine how well this model performs. Below are the imports needed for this task:
from sklearn.metrics import accuracy_score, classification_report, confusion_matrixWe can evaluate the performance using accuracy score, classification report, and confusion matrix. The code for this looks like:
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
matrix = confusion_matrix(y_test, y_pred)We got the following output from the classification model:
Accuracy of the model: 0.8569672131147541
Classification Report:
precision recall f1-score support
False 0.92 0.91 0.92 2064
True 0.53 0.56 0.55 376
accuracy 0.86 2440
macro avg 0.73 0.74 0.73 2440
weighted avg 0.86 0.86 0.86 2440
Confusion Matrix: [[1880 184]
[ 165 211]]Accuracy score measures the proportion of correctly classified instances out of the total number of instances in the dataset.
Some main information we can get from the classification report are precision, recall, and f1 score as shown above.
-
Precision tells us how accurate the positive predictions made is for that class (another way to define it is (true positive) / (true positive + false positive)). In another words, it shows how many predictions are actually correct out of the elements labeled as positive. Precision is 1 if a model was to be perfect and had no false positive.
-
Recall is the ratio between actual positives that were correctly classified and all actual positives (true positive / (true positive + false negative)). It is also known as sensitivity.
-
F1 score is defined as the harmonic mean of precision and recall; we can think of it as one number that takes both metrics into consideration.
-
Support is the number of actual occurrences of a class in the dataset. The higher the support, the more data points are associated with that class or itemset.
Now for the confusion matrix, from the first row, left to right, it holds the value for true negative, false positive, false negative, and true positive. For our data, respectively, this means:
-
Model correctly predicted that a customer did not make a purchase
-
Model predicted the customer made a purchase when it did not
-
Model predicted no purchase when there has been one made
-
Model correctly predicted that a customer made a purchase
Let’s take a look at another representation of the confusion matrix. Import the below:
from sklearn.metrics import ConfusionMatrixDisplayWe can use the below code to make the visualization.
display = ConfusionMatrixDisplay(confusion_matrix=matrix, display_labels=['False', 'True'])
display.plot()
plt.title('Confusion Matrix')
plt.show()The matrix should look like below:
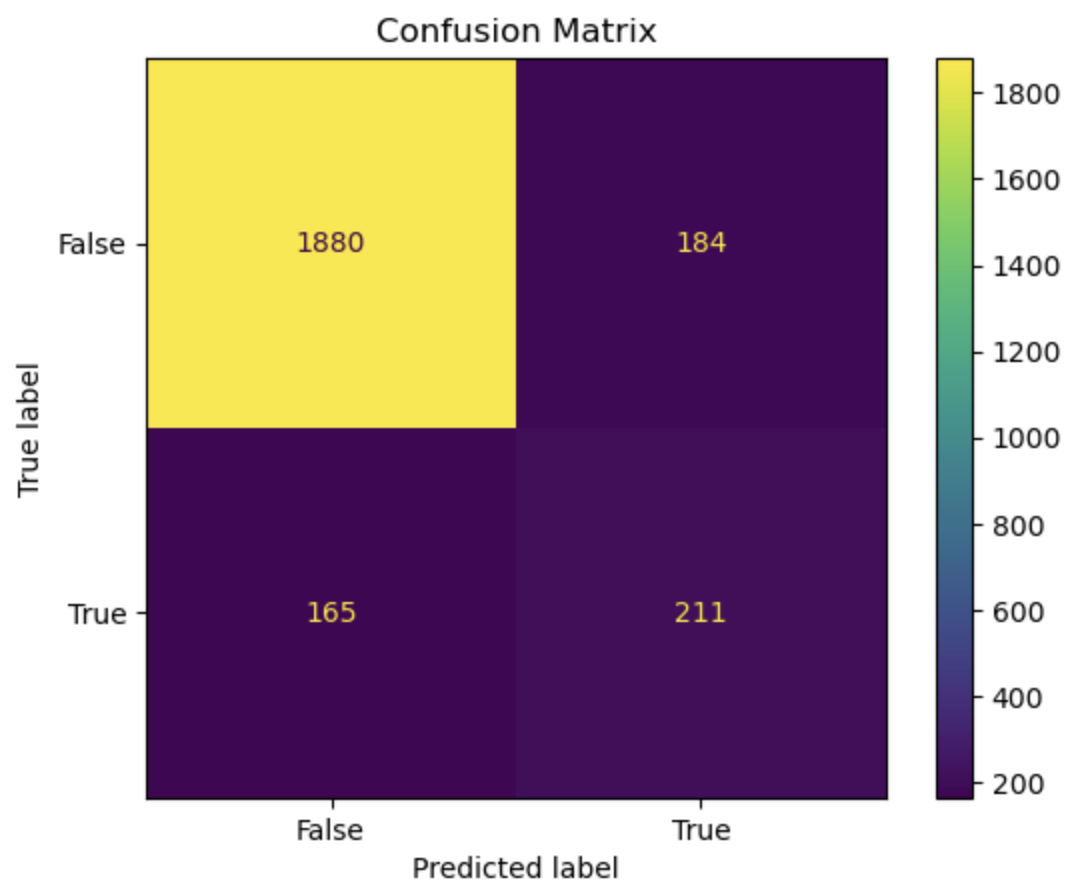
On the x-axis, we display all data points that the model predicted to belong to the selected class (either true or false). On the y-axis, we list all examples with the actual label for that class, for example, row 0 represents customers who actually made “no purchase.”
So again, applying the implication of the different sections of the matrix mentioned previously, we can see that there are 1880 correctly identified non purchase, 184 customers identified to have made a purchase when they did not, 165 missed actual purchases, and 211 correctly predicted purchases.
confusion_matrix() outputs an ndarray of the values, but with ConfusionMatrixDisplay(), we get the plotting object that can be used to visualize it better.
-
3a. We previously obtained a tree through
decision_tree.fit(). At the prediction part, the tree is traversed from root to a leaf based on each internal node’s condition and feature value. So,predict()obtains each leaf’s labels (true/false - purchase/no purchase) andy_predwill return an array of predicted labels. Each entry will contain the model’s prediction. This can get compared against the actual values. Generate the prediction forX_testwithdecision_tree.predict(). -
3b. Output the results of accuracy score, classification report, and the confusion matrix.
-
3c. Write a few sentences in your own words explaining the meaning and significance of accuracy. Also explain what information we are getting from the classification report and the confusion matrix. In our case, what do each of the outputted numbers signify in our confusion matrix?
Question 4 (2 points)
There are various parameters we can adjust to best work with the problem and dataset. We will take a look at max_depth, min_samples_leaf, and criterion.
-
max_depth: We limit the maximum depth of the tree with this parameter. Model will get more specific as we get deeper into the tree; however, better result is not always guaranteed with higher max_depth value.
-
min_samples_leaf: This is the minimum number of samples set for us to be allowed to be at a leaf node. Overfitting can happen if this value is too low since we could have branches with not enough samples or take more extreme values into higher consideration, and underfitting could happen otherwise, with the lack of ability to recognize patterns of data.
-
criterion: This lets us choose which function to use to split data at each node. It’s a part of finding the most appropriate feature for split to occur.
sklearnprovides three option:gini,entropy, andlog loss. It is defaulted to gini.
We will test using the following ranges of parameter values:
parameters = {'max_depth': list(range(1,26)),
'min_samples_leaf': list(range(1,26)),
'criterion': ['gini', 'entropy']}We can plot how the values for max depth affect the accuracy of the model.
depth = all_result[all_result['Parameter'] == 'max_depth']
plt.figure(figsize=(10,5))
plt.plot(depth['Value'], depth['Accuracy'])
plt.title('Accuracy vs. max_depth')
plt.xlabel('max_depth')
plt.ylabel('Accuracy')
plt.grid(True)
plt.show()-
4a. Using the
parametersgrid above, iterate through all combinations of the hyperparameters. For each combination, train a model on the data and make predictions. Then, calculate and record the accuracy score for each model. Finally, print the results showing the parameter values used (max_depth, min_samples_leaf, and criterion) along with the corresponding accuracy. -
4b. Plot how accuracy changes as the values for max depth changes. Create a plot for Accuracy vs min_samples_leaf also. Write 1-2 sentences about your observation.
-
4c. What conclusion can we make from this in regards to the effect different values of the parameters we tested have on the accuracy of the model? In our case, at which value of max_depth and min_samples_leaf do we get the best result? What can we interpret from the decrease in accuracy following the best max_depth value in the graph?
|
There are multiple options for picking the node’s attribute. Information gain and Gini index are two popular methods. The default in Information Gain: High information gain suggests the attribute results in a good split by the attribute. It uses entropy, value between 0 and 1 for binary classification, which measures the impurity of a set. An entropy of 0 indicates perfect purity (all samples belong to the same class), while an entropy of 1 represents maximum impurity (samples are evenly split between the classes). Formal definition of entropy for a set with c classes is: $Entropy = -\sum_{i=1}^{c}p_{i}log_{2}p_{i}$ where $p_i$ is the proportion of examples in class i. Information gain will show us the difference in uncertainty after a split. Gini Index: It is defined by $Impurity = 1 - \sum_{i=1}^{c} p_i^2$ This finds the probability that a dataset element is incorrectly classified by basing the calculation of the probability of each outcome. 0 index value implies perfect accuracy (we also say that it is pure), while higher index values indicate higher uncertainties. |
Question 5 (2 points)
As with other types of data analysis, we can also visualize the decision tree produced. To do so, make the following import:
from sklearn.tree import plot_treePlot the tree using:
plot_tree(decision_tree, feature_names=X.columns, filled=True)There are parameters you can adjust for the tree output. For example, adjusting max_depth will output only the number of depth you want to show in your tree, and other specific namings or preferred visualization.
Additionally, feature importance is a score corresponding to how much each feature contributes to the tree making the decision. The higher the value, the more important the feature is. It is easy to get this value using feature_importances_.
Now, we will make a comparison between users who made a purchase and did not make a purchase. The division is made by the variable "Revenue": if a purchase was made then the value is True, and False otherwise. Common, but useful information we can have is how their behavior, or the same variables' values differ. We will compare the top five features that contribute to revenue.
top5 = importance_score.nlargest(5).index.tolist()
avg = new_df.groupby('Revenue')[top5].mean()-
5a. Plot the decision tree we created in previous parts.
-
5b. Get top 5 useful features and output them. What implication does this have for online sales and customers?
-
5c. Plot the importance scores for all features in sorted order.
-
5d. Find the average values between top 5 features between the group who made a purchase and the group who did not. Output all computed values, as well the differences.
Question 6 (2 points)
We obtained an acceptable answer from the decision tree model. However, there are methods that can make models perform better. One common way is grid search, used for hyperparameter tuning. We saw earlier that parameters of decision tree affects the performance and the accuracy of the results. Grid search makes the optimization by testing all combination of parameter values from a set.
Let’s start with getting necessary import:
from sklearn.model_selection import GridSearchCVUse the same parameters as question 4 and set up grid search:
grid_search = GridSearchCV(estimator=decision_tree, param_grid=parameters)
grid_search.fit(X_train, y_train)
y_pred = grid_search.best_estimator_.predict(X_test)best_params_ stores the parameter combination that gives the best result. best_estimator_ gives the model with those specific parameters. best_score_ provides the highest average score over the cross validation folds in best parameter (scikit’s default cv value is 5). Cross validation splits the training data into equal random parts and in each iteration a different fold is used as test. The result is the average over all folds.
Grid search has the advantage of being straightforward and thorough since it tests every possible combination in the defined space, and it will find the optimal parameters as long as we are in that grid. However, it has the disadvantage of being computationally expensive if we have a large model or if the search space is large (you might notice that if we use the same parameter grid it might take a few minutes to finish running), and if the best parameters does not exist within the defined range, this method could fail to find it.
-
6a. Run decision tree model with grid search and output the new classification report. Also output the best parameters and best score found by grid search.
-
6b. Write a few sentences about the new result. How does this compare to the scores and accuracy obtained in question 4?
-
6c. Decision tree is one of the fundamental concepts to know, and they are very versatile while being simple to understand. However, there are other algorithms with better performance than decision trees. What are some disadvantages of using decision trees? In what cases should we avoid relying heavily on decision trees?
Submitting your Work
Once you have completed the questions, save your Jupyter notebook. You can then download the notebook and submit it to Gradescope.
-
firstname_lastname_project11.ipynb
|
You must double check your You will not receive full credit if your |