TDM 30100: Project 12 — 2022
Motivation: RESTful APIs are everywhere! At some point in time, it will likely be the source of some data that you will want to use. What better way to understand how to interact with APIs than building your own?
Context: This is the second to last project in a series around APIs. In this project, we will build a minimal API that does some basic operations, and in the following project we will build on top of that API and use templates to build a "frontend" for our API.
Scope: Python, fastapi, VSCode
Dataset(s)
The following questions will use the following dataset(s):
-
/anvil/projects/tdm/data/movies_and_tv/imdb.db
In addition, the following is an illustration of the database to help you understand the data.
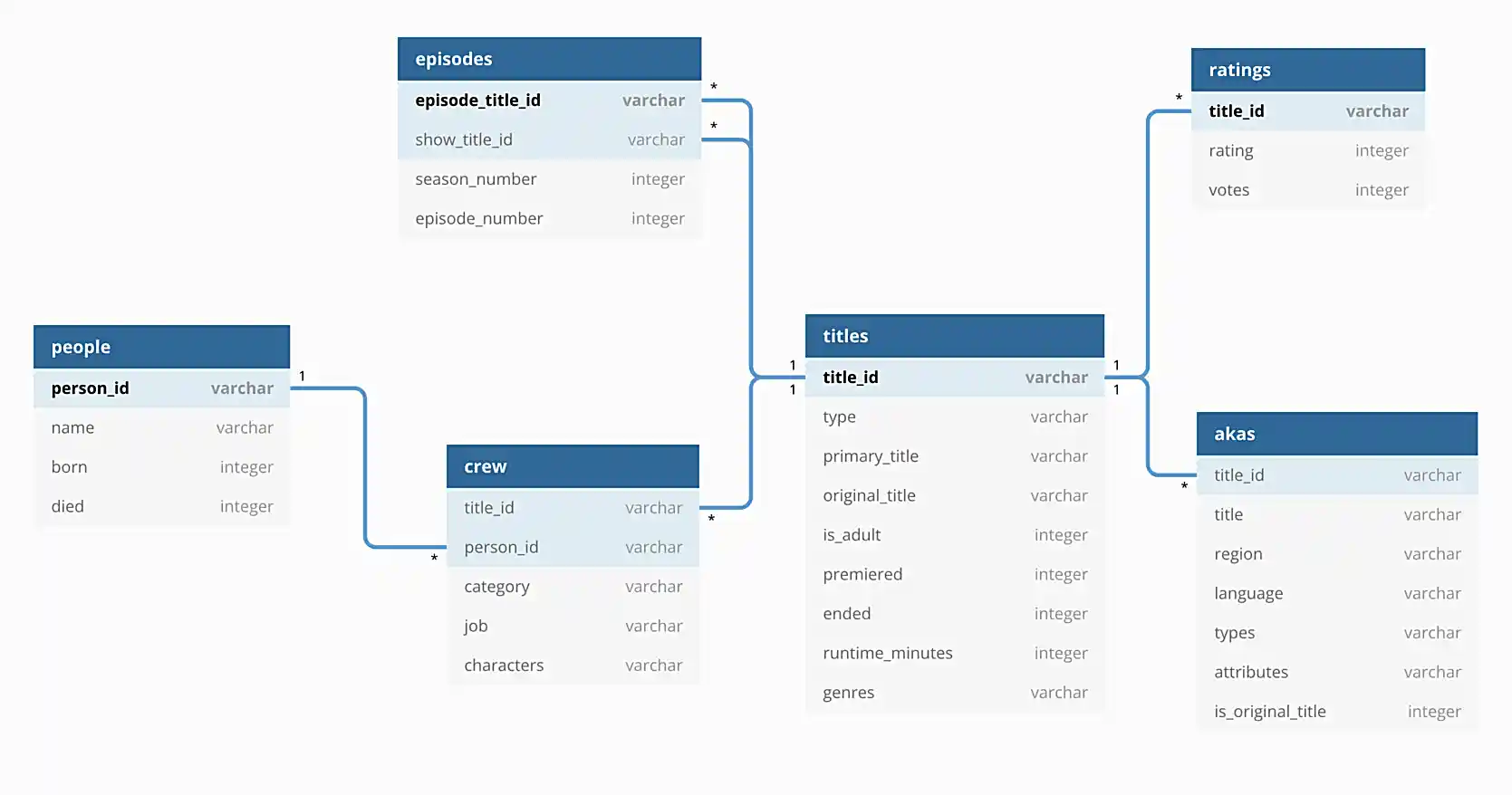
For this project, we will be using the imdb sqlite database. This database contains the data in the directory listed above.
Questions
Question 1
Let’s start by setting up our API, and getting a few things configured. This project will assume that you were able to connect and setup VSCode in the previous project. If you didn’t do this, please go back and do that now. That project (aside from some initially incorrect windows commands) is pretty straightforward and at the end you have a super cool setup and easy way to work on Anvil using VSCode!
-
Open VSCode and connect to Anvil.
-
Hold Cmd+Shift+P (or Ctrl+Shift+P) to open the command palette, search for "Terminal: Create new terminal" and hit enter. This will open a terminal in VSCode that is connected to Anvil.
-
Copy over our project template into your
$HOMEdirectory.cp -r /anvil/projects/tdm/etc/imdb $HOME -
Open the
$HOME/imdbdirectory in VSCode. -
Load up our
f2022-s2023Python environment by running the following in the terminal in VSCode.module use /anvil/projects/tdm/opt/core module load tdm module load python/f2022-s2023 -
Go ahead and test out the provided, minimal API by running the following in the terminal in VSCode.
find_port # returns a port, like 7777python3 -m uvicorn imdb.api:app --reload --port 7777 # replace 7777 with the port you got from find_port -
Open a browser on your computer and navigate to
localhost:7777, but be sure to replace 7777 with the port you got fromfind_port. You should see a message that says "Hello World!". This is a JSON response, which is why your browser is showing it in a nice format.
No need to turn anything in for this question — it is integral for all of the remaining questions.
-
Code used to solve this problem.
-
Output from running the code.
Question 2
If you check out api.py you will find two functions. The root function is responsible for the "Hello World" message you received in the previous question. As you can see, we returned the JSON response, which caused the data to be rendered that way. JSON is a data format that is very common in RESTful APIs. For simiplicity, we will be using JSON for all of our responses, today.
The other function, read_item, is responsible for the "hi there" stuff from the previous project. If you navigate to localhost:7777/hithere/alice you will see a webpage that displays the name "alice". The url path parameter {name} turns into a variable. So if you changed alice to joe, you would see "hi there joe" instead. This is a very common pattern in RESTful APIs.
We are going to keep things as "simple" as possible, because there are so many components to this sort of project that it is easy to get confused and have something go wrong. Our goal is to wire our API up to the database, imdb.db, and create an endpoint that returns some structured data (as JSON).
It is highly recommended to go through the official documentation tour. It is well written and may provide examples that help you understand something we do for this project, better.
Let’s start with our problem statement. We want links like the following to display data about the given title: localhost:7777/title/tt8946378. Where tt8946378 is the imdb.com title id for "Knives Out". Specifically, we want to start by displaying the: primary_title, premiered, and runtime_minutes from the titles table.
Before we can even think about displaying the data, we need to wire up our database. Create a new file in the imdb directory called database.py. Include the following content.
import os
import aiosql
import sqlite3
from dotenv import load_dotenv
from pathlib import Path
load_dotenv()
database_path = Path(os.getenv("DATABASE_PATH"))
queries = aiosql.from_path(Path(__file__).parents[0] / "queries.sql", "sqlite3")We are going to use the aiosql package to make queries to our database. This package is extremely simple (compared to other packages) and has (in my opinion) the best separation of SQL and Python code. It is also very easy to use (compared to other packages, at least). Let’s walk through the code.
-
load_dotenv()load the environment variables from a.envfile. Classically, the.envfile is used to store sensitive credentials, like database passwords. In our case, our database has no password, so to demonstrate we are going to put our database path in an environment variable instead.We haven’t created a
.envfile yet, let’s do that now! Create a text file named.envin your root directory (the outerimdbfolder) and add the following contents:envDATABASE_PATH=/anvil/projects/tdm/data/movies_and_tv/imdb.db
Now, after
load_dotenv()is called, theos.getenv("DATABASE_PATH")will return the path to our database,/anvil/projects/tdm/data/movies_and_tv/imdb.db. -
database_pathis simply the path loaded into a variable. -
queriesis an object that load up all of our SQL queries from a futurequeries.sqlfile, and allows us to easily make SQL queries from inside Python. We will give example of this later.
Thats it! We can then import the queries object in our other Python modules in order to make queries, cool!
No need to submit anything for this question either. The database.py file will be submitted at the end.
-
Code used to solve this problem.
-
Output from running the code.
Question 3
Okay, we "wired" our database up, but we need to actually make a query that returns all of the information we want to display, right?
Create a new file called queries.sql in the inner imdb directory. This file will contain all of our SQL queries. The "comments" inside this file are critical for our aiosql package to identify the queries and load them into our queries object. The following is an example of a queries.sql file and Python code that uses it to make queries on a fake database.
-- name: get_name_and_age -- Get name and age of object. SELECT name, age FROM my_table WHERE myid = :myid;
conn = sqlite3.connect("fake.db")
queries = aiosql.from_path("queries.sql", "sqlite3")
results = queries.get_name(conn, myid=1)
conn.close()
print(results)
# or, the following, which automatically closes the connection
queries = aiosql.from_path("queries.sql", "sqlite3")
conn = sqlite3.connect("fake.db")
with conn as c:
results = queries.get_name(c, myid=1)
print(results)[("bob", 42), ("alice", 37)]
Add a query called get_title to your queries.sql file. This query should return the primary_title, premiered, and runtime_minutes from the titles table.
In your api.py file, add a new function that will be used to eventually return a JSON with the title information. Call this function get_title.
For now, just use the queries object to make a query to the database, and have the function return whatever the query returns. Once implemented, test it out by navigating to localhost:7777/title/tt8946378 in your browser. You should see a (incorrectly) rendered response, with the info we wanted to display. We are getting there!
For this question, include a screenshot like the following, but for a different title.

|
If you use Chrome, your screenshot may look a bit different, that is OK. |
|
The |
-
Code used to solve this problem.
-
Output from running the code.
Question 4
Okay! We were able to display our data, but it is not formatted correctly, and without any context, it is hard to say what 130 represents (runtime in minutes). Let’s fix that by using the pydantic package to create a Title model. This model will be used to format our data before it is returned to the user. It is good practice to have all responses be formatted using pydantic — that way data is always returned in a consistent, expected format.
Read this section of the offical documentation.
Create a new file called schemas.py in the imdb directory. In this file, create a Title model that has all of the fields we want to display.
In your api.py file, update your get_title function to return a Title object instead of the raw data from the database.
|
To take a query result and convert it to a |
Navigate to localhost:7777/title/tt8946378 in your browser. You should see a correctly formatted response, with the info we wanted to display. Your result should look like the following image, but for a different title.

Please submit the following things for this project.
-
A
.ipynbfile with a screenshot for question 3 and 4 added. -
Your
api.pyfile. -
Your
database.pyfile. -
Your
queries.sqlfile. -
Your
schemas.pyfile.
Congratulations! You should feel accomplished! While it may not feel like you did much, you wired together a database and backend API, made SQL queries from within Python, and formatted your data using pydantic models. That is a lot of work! Great job! Happy thanksgiving!
|
If you have any questions, please post in Piazza and we will do our best to help you out! |
-
Code used to solve this problem.
-
Output from running the code.
Question 5 (optional, 0 points)
Read the documentation and update your API to include the genres in your response!
-
Code used to solve this problem.
-
Output from running the code.
|
Please make sure to double check that your submission is complete, and contains all of your code and output before submitting. If you are on a spotty internet connection, it is recommended to download your submission after submitting it to make sure what you think you submitted, was what you actually submitted. In addition, please review our submission guidelines before submitting your project. |