TDM 20100: Project 10 — 2022
Motivation: Being able to use results of queries as tables in new queries (also known as writing sub-queries), and calculating values like MIN, MAX, and AVG in aggregate are key skills to have in order to write more complex queries. In this project we will learn about aliasing, writing sub-queries, and calculating aggregate values.
Context: We are in the middle of a series of projects focused on working with databases and SQL. In this project we introduce aliasing, sub-queries, and calculating aggregate values!
Scope: SQL, SQL in R
Dataset(s)
The following questions will use the following dataset(s):
-
/anvil/projects/tdm/data/movies_and_tv/imdb.db
In addition, the following is an illustration of the database to help you understand the data.
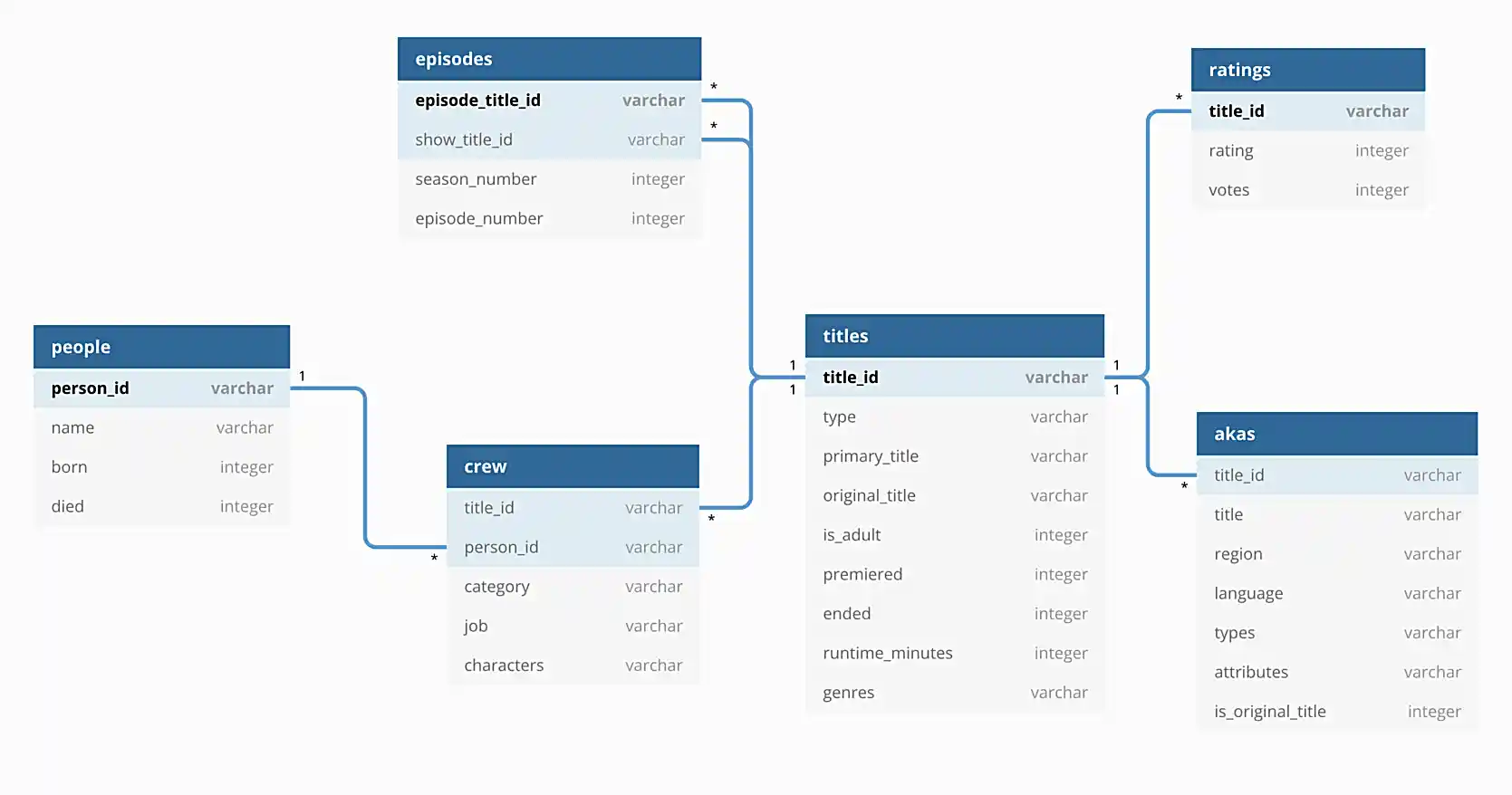
For this project, we will be using the imdb sqlite database. This database contains the data in the directory listed above.
To run SQL queries in a Jupyter Lab notebook, first run the following in a cell at the top of your notebook to establish a connection with the database.
%sql sqlite:////anvil/projects/tdm/data/movies_and_tv/imdb.dbFor every following cell where you want to run a SQL query, prepend %%sql to the top of the cell — just like we do for R or bash cells.
Questions
Question 1
Let’s say we are interested in the Marvel Cinematic Universe (MCU). We could write the following query to get the titles of all the movies in the MCU (at least, available in our database).
SELECT premiered, COUNT(*) FROM titles WHERE title_id IN ('tt0371746', 'tt0800080', 'tt1228705', 'tt0800369', 'tt0458339', 'tt0848228', 'tt1300854', 'tt1981115', 'tt1843866', 'tt2015381', 'tt2395427', 'tt0478970', 'tt3498820', 'tt1211837', 'tt3896198', 'tt2250912', 'tt3501632', 'tt1825683', 'tt4154756', 'tt5095030', 'tt4154664', 'tt4154796', 'tt6320628', 'tt3480822', 'tt9032400', 'tt9376612', 'tt9419884', 'tt10648342', 'tt9114286') GROUP BY premiered;The result would be a perfectly good-looking table. Now, with that being said, are the headers good-looking? Is it clear what data each column contains? I don’t know about you, but COUNT(*) as a header is not very clear. Aliasing is a great way to not only make the headers look good, but it can also be used to reduce the text in a query by giving some intermediate results a shorter name.
Fix the query so that the headers are year and movie count, respectively.
-
Code used to solve this problem.
-
Output from running the code.
Question 2
Okay, let’s say we are interested in modifying our query from question (1) to get the percentage of MCU movies released in each year. Essentially, we want the count for each group, divided by the total count of all the movies in the MCU.
We can achieve this using a subquery. A subquery is a query that is used to get a smaller result set from a larger result set.
Write a query that returns the total count of the movies in the MCU, and then use it as a subquery to get the percentage of MCU movies released in each year.
|
You do not need to change the query from question (1), rather, you just need to add to the query. |
|
You can directly divide |
|
Your initial result may seem very wrong (no fractions at all!) this is OK — we will fix this in the next question. |
|
Use aliasing to rename the new column to |
-
Code used to solve this problem.
-
Output from running the code.
Question 3
Okay, if you did question (2) correctly, you should have got a result that looks a lot like:
year,movie count,percentage 2008, 2, 0 2010, 1, 0 2011, 2, 0 ...
What is going on?
The AS keyword can also be used to cast types. Some of you may or may not be familiar with a feature of many programming languages. Common in many programming languages is an "integer" type — which is for numeric data without a decimal place, and a "float" type — which is for numeric data with a decimal place. In many languages, if you were to do the following, you’d get what may be unexpected output.
9/42
Since both of the values are integers, the result will truncate the decimal place. In other words, the result will be 2, instead of 2.25.
In Python, they’ve made changes so this doesn’t happen.
9/42.25
However, if we want the "regular" functionality we can use the // operator.
9//42
Okay, sqlite does this as well.
SELECT 9/4 as result;result 2
This is why we are getting 0’s for the percentage column!
How do we fix this? The following is an example.
SELECT CAST(9 AS real)/4 as result;result 2.25
|
Here, "real" represents "float" or "double" — it is another way of saying a number with a decimal place. |
|
When you do arithmetic with an integer and a real/float, the result will be a real/float. This is why our result is a real even though 50% of our values are integers. |
Fix the query so that the results look something like:
year, movie count, percentage 2008, 2, 0.0689... 2010, 1, 0.034482... 2011, 2, 0.0689...
|
You can read more about |
-
Code used to solve this problem.
-
Output from running the code.
Question 4
You now know 2 different applications of the AS keyword, and you also know how to use a query as a subquery, great!
In the previous project, we were introduced to aggregate functions. We used the GROUP BY clause to group our results by the premiered column in this project too! We know we can use the WHERE clause to filter our results, but what if we wanted to filter our results based on an aggregated column?
Modify our query from question (3) to print only the rows where the movie count is greater than 2.
|
See this article for more information on the |
-
Code used to solve this problem.
-
Output from running the code.
Question 5
Write a query that returns the average number of words in the primary_title column, by year, and only for years where the average number of words in the primary_title is less than 3.
Look at the results. Which year had the lowest average number of words in the primary_title column (no need to write another query for this, just eyeball it)?
|
See here. Replace "@String" with the column you want to count the words in. |
|
If you got it right, there should be 15 rows in the output. |
-
Code used to solve this problem.
-
Output from running the code.
|
Please make sure to double check that your submission is complete, and contains all of your code and output before submitting. If you are on a spotty internet connection, it is recommended to download your submission after submitting it to make sure what you think you submitted, was what you actually submitted. In addition, please review our submission guidelines before submitting your project. |