401 Project 11 - Regression: Artificial Neural Networks (ANN) - Multilayer Perceptron (MLP)
Project Objectives
In this project, we will be taking some of what we learned from our Perceptron model and expand upon it to create a functional Artificial Neural Network (ANN) model, specifically a Multi Layer Perceptron (MLP). We will use the same dataset (Boston Housing) to compare the performance of our original perceptron with the new ANN.
Questions
Question 1 (2 points)
Across this project and the next one, we will be learning about and implementing neural networks. In this project, we will expand upon the perceptron model we implemented in the previous project to create a more complex model known as a Multilayer Perceptron (MLP). This MLP is a form of ANN that consists of multiple layers, where each layer consists of multiple perceptrons. In the next project, we will be implementing a convolutional neural network (CNN), which is a type of ANN that is particularly suited for data that has spatial relationships, such as images or time series.
In this project, we will use the same dataset as the previous project to compare the performance of our original perceptron model with the new MLP model. We will use the same features and target variable as before. Please run the following code to load the dataset and split it into training and testing sets:
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
df = pd.read_csv('/anvil/projects/tdm/data/boston_housing/boston.csv')
X = df.drop(columns=['MEDV'])
y = df[['MEDV']]
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=7)
y_train = y_train.to_numpy()
y_test = y_test.to_numpy()Additionally, please copy these solutions for activation functions, their derivatives, and evaluation metrics into your notebook:
import numpy as np
def linear(x):
return x
def linear_d(x):
return np.ones_like(np.atleast_1d(x))
def relu(x):
return np.maximum(x, 0)
def relu_d(x):
return np.where(x>0, 1, 0)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_d(x):
return sigmoid(x) * (1-x)
def tanh(x):
return np.tanh(x)
def tanh_d(x):
return 1 - (tanh(x)**2)
def get_mse(y, y_pred):
return np.mean((y - y_pred) ** 2)
def get_rmse(y, y_pred):
return np.sqrt(get_mse(y,y_pred))
def get_mae(y, y_pred):
return np.mean(np.abs(y - y_pred))
def get_r_squared(y, y_pred):
return 1 - np.sum((y - y_pred) ** 2) / np.sum((y - np.mean(y)) ** 2)
derivative_functions = {
'relu': relu_d,
'sigmoid': sigmoid_d,
'linear': linear_d,
'tanh': tanh_d
}
activation_functions = {
'relu': relu,
'sigmoid': sigmoid,
'linear': linear,
'tanh': tanh
}Firstly, let’s discuss what the structure of a Multilayer Perceptron looks like. An MLP typically consists of an input layer, some number of hidden layers, and an output layer. Each layer consists of multiple nodes or perceptrons, each with their own weights and biases. Each node passes its output to every node in the next layer, creating a fully connected network. The diagram below shows a simple MLP with an input layer consisting of 3 input nodes, 2 hidden layers with 6 and 4 nodes respectively, and an output layer with 1 node.
|
In our MLP, the input layer will simply be the features of our dataset, so the features will be passed directly to the first hidden layer. |
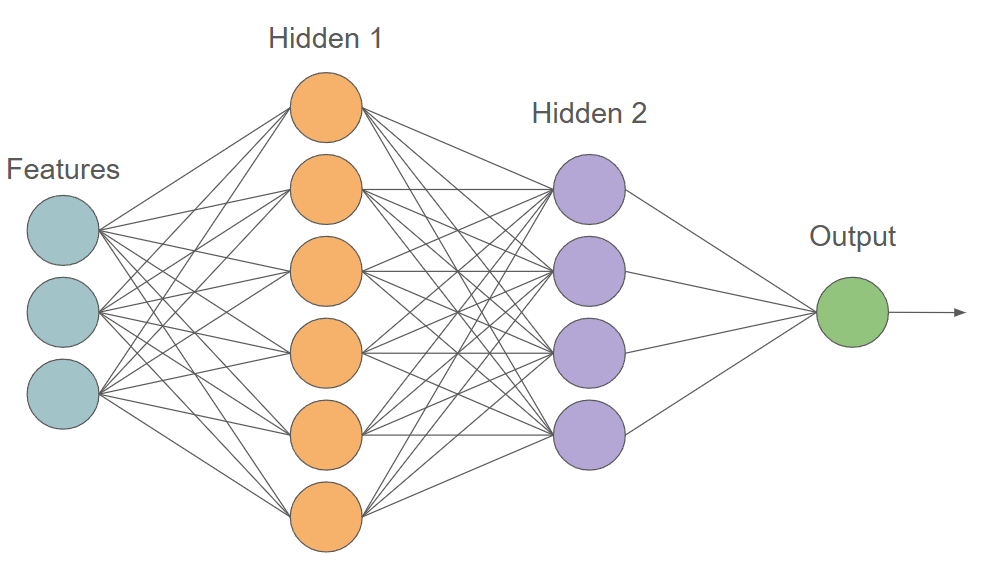
Throughout this project, we will be implementing 3 main classes: 'Node', 'Layer', and 'MLP'. The 'Node' class represents a single neuron in our network, and will store its weights, biases, and a forward function to calculate its output. The 'Layer' class represents one of the layers in our network, and stores a list of nodes, an activation method and its derivative, and a forward function to calculate the output of all nodes in the layer. The 'MLP' class represents the entire network, and stores a list of layers, a forward function to calculate the output of the entire network, a train function to train the model, and a test function to evaluate the model using our evaluation metrics.
In this question, we will implement the 'Node' class. Please complete the following code to implement the 'Node' class:
class Node:
def __init__(self, input_size):
# given input size (number of features for the node):
# initialize self.weights to random values with np.random.randn
# initialize self.bias to 0
pass
def forward(self, inputs):
# calculate the dot product of the inputs and weights, add the bias, and return the result. Same as the perceptron model.
passYou can test your implementation by running the following code:
np.random.seed(11)
node = Node(3)
inputs = np.array([1, 2, 3])
output = node.forward(inputs)
print(output) # should print -0.276386648990842-
Completed Node class
-
Output of the testing code
Question 2 (2 points)
Next, we will implement our 'Layer' class. The 'Layer' class is slightly more complex, as it will store a list of nodes, an activation function and its derivative, and a forward function to calculate the output of all nodes in the layer and apply the activation_function. Please complete the following code to implement the 'Layer' class:
class Layer:
def __init__(self, num_nodes, input_size, activation='relu'):
# set self.nodes to be a list of Node objects, with length num_nodes
# check if the activation function is supported (a key in one of the provided dictionaries). if not, raise a ValueError
# set self.activation_func and self.activation_derivative to the correct functions from the dictionaries
pass
def forward(self, inputs):
# Create an list of the forward pass output of each node in the layer
# Apply the activation function to the list of outputs and return the result
passYou can test your implementation by running the following code:
np.random.seed(11)
layer = Layer(3, 3, activation='linear')
inputs = np.array([1, 2, 3])
output = layer.forward(inputs)
print(output) # should print [-0.27638665 -3.62878191 1.35732812]-
Completed Layer class
-
Output of the testing code
Question 3 (2 points)
Now that our Node and Layer class are correct, we can move on to implementing the 'MLP' class. This class will store our list of layers, a forward function to calculate output of the model, a train function to train the model, and a test function to evaluate the model using our evaluation metrics. In this question, we will implement just the initialization, forward, and test functions. Please begin completing the following 'MLP' class outline:
class MLP:
def __init__(self, layer_sizes, activations):
# we are given 'layer_sizes', a list of numbers, where each number is the number of nodes in the layer.
# The first layer should be the number of features in the input data
# We only need to create the hidden and output layers, as the input layer is simply our input data
# For example, if layer_sizes = [4, 5, 2], we should set self.layers = [Layer(5, 4), Layer(2, 5)]
# Additionally, we are given 'activations', a list of strings, where each string is the name of the activation function for the corresponding layer
# len(activations) will always be len(layer_sizes) - 1, as the input layer does not have an activation function
# Please set self.layers to be a list of Layer objects, with the correct number of nodes, input size, and activation function.
pass
def forward(self, inputs):
# for each layer in the MLP, call the forward method with the output of the previous layer
# then, return the final output
pass
def train(self, X, y, epochs=100, learning_rate=0.0001):
for epoch in range(epochs):
for i in range(len(X)):
# Store the output of each layer in a list, starting with the input data
# You should have a list that looks like [X[i], layer1_output, layer2_output, ..., outputlayer_output]
# find the error, target value - output value
# Now, we can perform our backpropagation to update the weights and biases of our model
# We need to start at the last layer and work our way back to the first layer
for j in reversed(range(len(self.layers))):
# get the layer object at index j
# get the layer_input and layer_output corresponding to the layer. Remember, self.layers does not contain the input, but outputs list above does
# calculate the gradient for each node in the layer
# same as the perceptron model, -error * activation_derivative(layer_output).
# However, this time it is a vector, as we are calculating the activation_derivative for everything in the layer at once
# Now, we must update the error for the next layer.
# This is so that we can calculate the gradient for the next layer
# This is done by taking the dot product of our gradients by the weights of each node in the current layer
# Finally, we can update the weights and biases of each node in the current layer
# Remember, our gradient is a list, so each node in the layer will have its own corresponding gradient
# Otherwise, the process is the same as the perceptron model.
for k, node in enumerate(layer.nodes):
# update the weights and bias of the node
pass
def test(self, X, y, methods=['mse', 'rmse', 'mae', 'r_squared']):
# Calculate metrics for each method
# First, get the predictions for each input in X
# Then, for each method the user wants, call the corresponding function with input y and predictions
# Finally return a dictionary with the metric as key and the result as value
passTo test your implementation of the initialization, forward, and test functions, you can run the following code:
np.random.seed(11)
mlp = MLP([3, 4, 2], ['relu', 'linear'])
inputs = np.array([1, 2, 3])
output = mlp.forward(inputs)
print(output) # should print [-1.77205771 -0.04217909]
X = np.array([[1, 2, 3], [4, 5, 6]])
y = np.array([[0, 1], [1, 0]])
metrics = mlp.test(X, y)
print(metrics) # should print {'mse': 2.698031745867772, 'rmse': 1.6425686426654358, 'mae': 1.6083905323341714, 'r_squared': -9.792126983471087}-
Implementation of the MLP class 'init', 'forward', and 'test' methods
-
Output of the testing code
Question 4 (2 points)
Now that we have all of our helper functions, we can work on training our model. This process will be very similar to the perceptron model we implemented in the previous project, but with a few key differences. Please read the helping comments in the 'train' method of the 'MLP' class and complete the code to train the model.
To test your implementation, we will do 2 things:
Firstly, we will test our MLP model as just a single perceptron, with the same parameters and starting weights as Questions 4 and 5 in the previous project. If everything is implemented correctly, the output of the perceptron last project and the single perceptron MLP here should be the same.
np.random.seed(3)
mlp = MLP([X_train.shape[1], 1], ['linear'])
mlp.layers[0].nodes[0].weights = np.zeros(X_train.shape[1])
mlp.train(X_train, y_train, epochs=100, learning_rate=0.01)
print(mlp.layers[0].nodes[0].weights) # should print the same weights as the perceptron model
print(mlp.layers[0].nodes[0].bias) # should print the same bias as the perceptron model
mlp.test(X_test, y_test) # should print the same metrics as the perceptron modelNext, we can test our MLP model with multiple nodes and layers.
|
Now that we have multiple nodes and layers, these code cells may take a while to run. Please be patient and give yourself enough time to run these tests. |
np.random.seed(3)
mlp = MLP([X_train.shape[1], 2, 3, 1], ['linear','linear','linear'])
mlp.train(X_train, y_train, epochs=1000, learning_rate=0.0001)
mlp.test(X_test, y_test) # should output {'mse': 17.78775654565155, 'rmse': 4.217553383853197, 'mae': 3.2032070058415836, 'r_squared': 0.7119015806656752}-
Implementation of the 'train' method in the 'MLP' class
-
Output of perceptron model testing code
-
Output of MLP model testing code
Question 5 (2 points)
If you remember from the previous project, with only a single perceptron there is a limit to the how we can try to improve the model. We can train it for more epochs, or adjust its learning rate. Additionally, we can investigate how SGD, BGD, and MBGD affect its training, but there isn’t much beyond that. However, now that we have an MLP model, we can experiment with different numbers of layers, nodes in each layer, the activation functions of those layers, as well as the learning rate, number of epochs, and SGD vs BGD vs MBGD.
Please experiment with different numbers of layers, number of nodes in each layer, activation functions, learning rates, number of epochs, and/or SGD vs BGD vs MBGD. For this question, please provide a brief summary of what you tried, and what you noticed. You are not required to try and improve the metrics of the model, but you are welcome to try if you would like.
|
This model is VERY sensitive to the learning rate, number of epochs, and the number of nodes in each layer. If you are not seeing any improvement in your metrics, try adjusting these parameters. Additionally, the model may take a long time to train, so please give yourself enough time to experiment with different parameters. It is recommended to have a maximum of 3 hidden layers (not including the input and output layers) and a maximum of 10 nodes in each layer to ensure your model trains in a reasonable amount of time. A common problem you may face is the vanishing gradient and exploding gradient problem. This is when the gradients of the weights become very small or large, respectively, and the model is unable to learn. You will know you have exploding gradients if your outputs become nan, inf, or some extremely large number. You may have vanishing gradients if your model seems to not be learning at all. Learning rate and number of epochs are the most common ways to combat these problems, but you may also need to experiment with different activation functions and the number of nodes and layers. |
-
Student has some code that shows them adjusting parameters and experimenting with different configurations
-
Student has a brief summary of what they tried and what they noticed
Question 6 (2 points)
Currently, we are simply filling the weights of our nodes with random values. However, depending on the activation function of the layer, we may want to initialize our weights differently to help promote model convergence and avoid potential gradient problems. There are many different weight initialization methods depending on the activation function, however there are 2 extremely popular choices: Xavier Initialization and He Initialization. These methods are described below:
| Initialization Method | Description | Formula |
|---|---|---|
Xavier |
Commonly used for tanh and sigmoid activation functions to help ensure that the variance is maintained throughout the model |
$W =np.random.normal(0, np.sqrt(2/(input\_size+output\_size)), input\_size)$ |
He |
Used for ReLU based activation functions to ensure that they do not vanish |
$W = np.random.normal(0, np.sqrt(2/inputs), inputs)$ |
| The form of Xavier depicted above is for a normal distribution. However, there also exists a uniform distribution version of Xavier Initialization, with the formula $W = np.random.uniform(-\sqrt{6/(input\_size+output\_size)}, \sqrt{6/(input\_size+output\_size)}, input\_size)$. You are not required to implement this version, but you are welcome to if you would like. |
Please modify the 3 main classes to be able to change the initialization function of the weights. The MLP class will now take 3 lists as input: 'layer_sizes', 'activations', and 'initializations'. 'initializations' will be a list of strings, where each string is the name of the initialization function for the corresponding layer. The valid values for this list should be 'random', 'xavier', and 'he'. You will need to modify the 'Node' class to accept an initialization method, and modify the 'Layer' class to pass this method to the 'Node' class. You will also need to modify the 'MLP' class to pass the initialization method to the 'Layer' class.
After you have implemented this, run the below code to visualize the distributions of the weights to confirm that they are being initialized correctly.
np.random.seed(1)
initialized_mlp = MLP([80,80,80,80], ['relu','relu','relu'], ['random','xavier','he'])
original_random = initialized_mlp.layers[0].nodes[0].weights
xavier = initialized_mlp.layers[1].nodes[0].weights
he = initialized_mlp.layers[2].nodes[0].weights
import matplotlib.pyplot as plt
plt.hist(original_random, bins=50, alpha=0.5, label='Random')
plt.hist(xavier, bins=50, alpha=0.5, label='Xavier')
plt.hist(he, bins=50, alpha=0.5, label='He')
plt.legend(loc='upper right')
plt.show()-
Implementation of the 'initializations' parameter in the 'MLP' class
-
Modification of the 'Node' and 'Layer' classes to accept and pass the initialization method
-
Output of the testing code
Submitting your Work
-
firstname_lastname_project11.ipynb
|
You must double check your You will not receive full credit if your |