TDM 20100: Project 1 — 2022
Motivation: It’s been a long summer! Last year, you got some exposure to both R and Python. This semester, we will venture away from R and Python, and focus on UNIX utilities like sort, awk, grep, and sed. While Python and R are extremely powerful tools that can solve many problems — they aren’t always the best tool for the job. UNIX utilities can be an incredibly efficient way to solve problems that would be much less efficient using R or Python. In addition, there will be a variety of projects where we explore SQL using sqlite3 and MySQL/MariaDB.
We will start slowly, however, by learning about Jupyter Lab. This year, instead of using RStudio Server, we will be using Jupyter Lab. In this project we will become familiar with the new environment, review some, and prepare for the rest of the semester.
Context: This is the first project of the semester! We will start with some review, and set the "scene" to learn about some powerful UNIX utilities, and SQL the rest of the semester.
Scope: Jupyter Lab, R, Python, Anvil, markdown
Dataset(s)
The following questions will use the following dataset(s):
-
/anvil/projects/tdm/data/flights/subset/1991.csv -
/anvil/projects/tdm/data/movies_and_tv/imdb.db
Questions
Question 1
For this course, projects will be solved using the Anvil computing cluster.
Each cluster is a collection of nodes. Each node is an individual machine, with a processor and memory (RAM). Use the information on the provided webpages to calculate how many cores and how much memory is available in total for the Anvil "sub-clusters".
Take a minute and figure out how many cores and how much memory is available on your own computer. If you do not have a computer of your own, work with a friend to see how many cores there are, and how much memory is available, on their computer.
|
Last year, we used the Brown computing cluster. Compare the specs of Anvil and Brown — which one is more powerful? |
-
A sentence explaining how many cores and how much memory is available, in total, across all nodes in the sub-clusters on Anvil.
-
A sentence explaining how many cores and how much memory is available, in total, for your own computer.
-
Code used to solve this problem.
-
Output from running the code.
Question 2
Like the previous year we will be using Jupyter Lab on the Anvil cluster. Let’s begin by launching your own private instance of Jupyter Lab using a small portion of the compute cluster.
Navigate and login to ondemand.anvil.rcac.purdue.edu using your ACCESS credentials (and Duo). You will be met with a screen, with lots of options. Don’t worry, however, the next steps are very straightforward.
|
If you did not (yet) setup your 2-factor authentication credentials with Duo, you can go back to Step 9 and setup the credentials here: the-examples-book.com/starter-guides/anvil/access-setup |
Towards the middle of the top menu, there will be an item labeled My Interactive Sessions, click on My Interactive Sessions. On the left-hand side of the screen you will be presented with a new menu. You will see that there are a few different sections: Bioinformatics, Interactive Apps, and The Data Mine. Under "The Data Mine" section, you should see a button that says Jupyter Notebook, click on Jupyter Notebook.
If everything was successful, you should see a screen similar to the following.
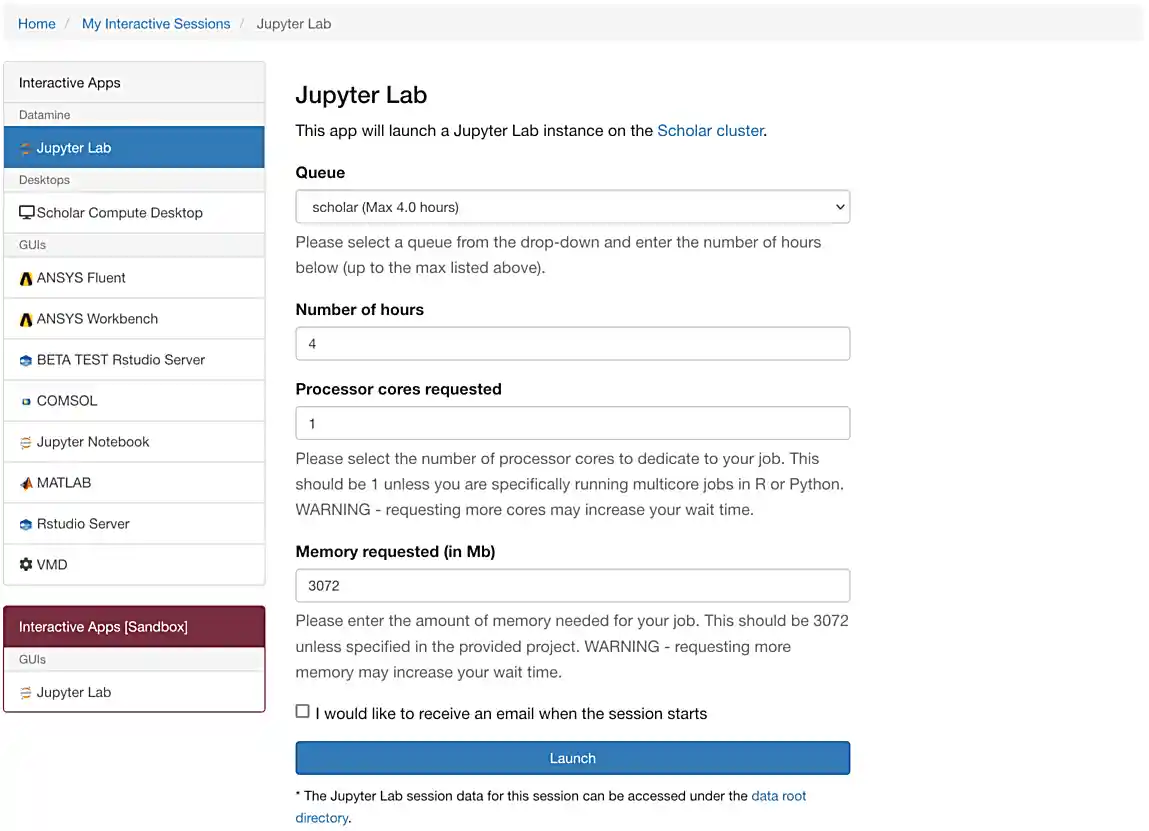
Make sure that your selection matches the selection in Figure 1. Once satisfied, click on Launch. Behind the scenes, OnDemand launches a job to run Jupyter Lab. This job has access to 2 CPU cores and 3800 Mb.
|
It is OK to not understand what that means yet, we will learn more about this in TDM 30100. For the curious, however, if you were to open a terminal session in Anvil and run the following, you would see your job queued up. |
|
If you select 4000 Mb of memory instead of 3800 Mb, you will end up getting 3 CPU cores instead of 2. OnDemand tries to balance the memory to CPU ratio to be about 1900 Mb per CPU core. |
We use the Anvil cluster because it provides a consistent, powerful environment for all of our students, and it enables us to easily share massive data sets with the entire Data Mine.
After a few seconds, your screen will update and a new button will appear labeled Connect to Jupyter. Click on Connect to Jupyter to launch your Jupyter Lab instance. Upon a successful launch, you will be presented with a screen with a variety of kernel options. It will look similar to the following.
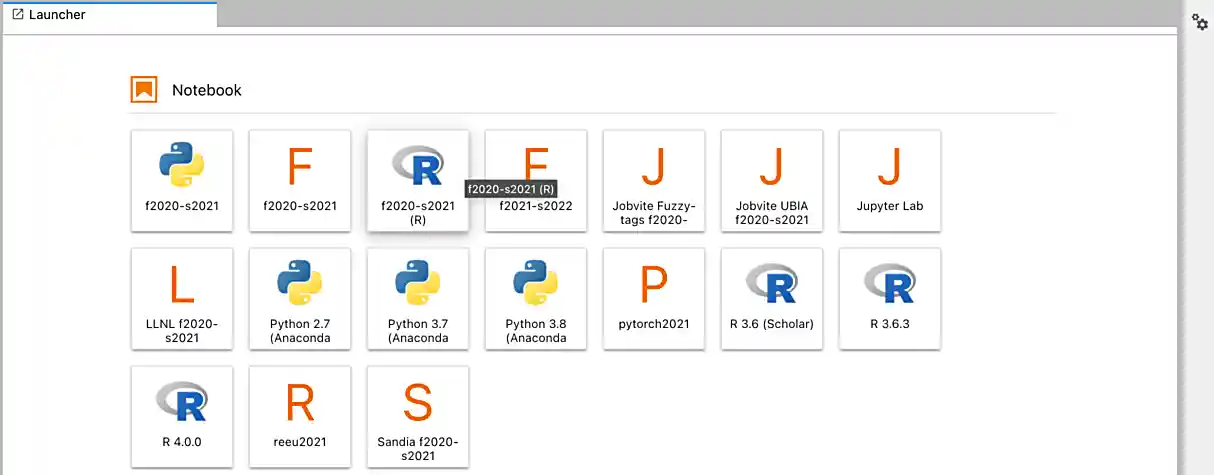
There are 2 primary options that you will need to know about.
- f2022-s2023
-
The course kernel where Python code is run without any extra work, and you have the ability to run R code or SQL queries in the same environment.
|
To learn more about how to run R code or SQL queries using this kernel, see our template page. |
- f2022-s2023-r
-
An alternative, native R kernel that you can use for projects with just R code. When using this environment, you will not need to prepend
%%Rto the top of each code cell.
For now, let’s focus on the f2022-s2023 kernel. Click on f2022-s2023, and a fresh notebook will be created for you.
|
Soon, we’ll have the f2022-s2023-r kernel available and ready to use! |
Test it out! Run the following code in a new cell. This code runs the hostname command and will reveal which node your Jupyter Lab instance is running on. What is the name of the node on Anvil that you are running on?
import socket
print(socket.gethostname())|
To run the code in a code cell, you can either press Ctrl+Enter on your keyboard or click the small "Play" button in the notebook menu. |
-
Code used to solve this problem in a "code" cell.
-
Output from running the code (the name of the node on Anvil that you are running on).
Question 3
In the upper right-hand corner of your notebook, you will see the current kernel for the notebook, f2022-s2023. If you click on this name you will have the option to swap kernels out — no need to do this yet, but it is good to know!
Practice running the following examples.
- python
my_list = [1, 2, 3]
print(f'My list is: {my_list}')- SQL
%sql sqlite:////anvil/projects/tdm/data/movies_and_tv/imdb.db%%sql
SELECT * FROM titles LIMIT 5;|
In a previous semester, you’d need to load the sql extension first — this is no longer needed as we’ve made a few improvements! |
- bash
%%bash
awk -F, '{miles=miles+$19}END{print "Miles: " miles, "\nKilometers:" miles*1.609344}' /anvil/projects/tdm/data/flights/subset/1991.csv|
To learn more about how to run various types of code using this kernel, see our template page. |
-
Code used to solve this problem.
-
Output from running the code.
Question 4
This year, the first step to starting any project should be to download and/or copy our project template (which can also be found on Anvil at /anvil/projects/tdm/etc/project_template.ipynb).
Open the project template and save it into your home directory, in a new notebook named firstname-lastname-project01.ipynb.
There are 2 main types of cells in a notebook: code cells (which contain code which you can run), and markdown cells (which contain markdown text which you can render into nicely formatted text). How many cells of each type are there in this template by default?
Fill out the project template, replacing the default text with your own information, and transferring all work you’ve done up until this point into your new notebook. If a category is not applicable to you (for example, if you did not work on this project with someone else), put N/A.
-
How many of each types of cells are there in the default template?
Question 5
Markdown is well worth learning about. You may already be a Markdown expert, however, more practice never hurts.
Create a Markdown cell in your notebook.
Create both an ordered and unordered list. Create an unordered list with 3 of your favorite academic interests (some examples could include: machine learning, operating systems, forensic accounting, etc.). Create another ordered list that ranks your academic interests in order of most-interested to least-interested. To practice markdown, embolden at least 1 item in you list, italicize at least 1 item in your list, and make at least 1 item in your list formatted like code.
|
You can quickly get started with Markdown using this cheat sheet: www.markdownguide.org/cheat-sheet/ |
|
Don’t forget to "run" your markdown cells by clicking the small "Play" button in the notebook menu. Running a markdown cell will render the text in the cell with all of the formatting you specified. Your unordered lists will be bulleted and your ordered lists will be numbered. |
-
Code used to solve this problem.
-
Output from running the code.
Question 6
Browse www.linkedin.com and read some profiles. Pay special attention to accounts with an "About" section. Write your own personal "About" section using Markdown in a new Markdown cell. Include the following (at a minimum):
-
A header for this section (your choice of size) that says "About".
A Markdown header is a line of text at the top of a Markdown cell that begins with one or more
#. -
The text of your personal "About" section that you would feel comfortable uploading to LinkedIn.
-
In the about section, for the sake of learning markdown, include at least 1 link using Markdown’s link syntax.
-
Code used to solve this problem.
-
Output from running the code.
Question 7
Review your Python and R skills. For each language, choose at least 1 dataset from /anvil/projects/tdm/data, and analyze it. Both solutions should include at least 1 custom function, and at least 1 graphic output. Make sure your code is complete, and well-commented. Include a markdown cell with your short analysis (1 sentence is fine), for each language.
-
Code used to solve this problem.
-
Output from running the code.
|
Please make sure to double check that your submission is complete, and contains all of your code and output before submitting. If you are on a spotty internet connection, it is recommended to download your submission after submitting it to make sure what you think you submitted, was what you actually submitted. In addition, please review our submission guidelines before submitting your project. |